この記事は、最適化のしきい値に関するシリーズの4番目です。このシリーズでは、データのグループ化と集約、SQL Serverが使用できるさまざまなアルゴリズム、およびアルゴリズムの選択に役立つコストモデルについて説明します。この記事では、並列処理の考慮事項に焦点を当てます。 SQL Serverで使用できるさまざまな並列処理戦略、シリアルプランとパラレルプランのどちらかを選択するためのしきい値、およびSQLServerがコスト計算の並列処理の程度と呼ばれる概念を使用して適用するコスト計算ロジックについて説明します。 (原価計算のDOP)。
例では、PerformanceV3サンプルデータベースのdbo.Ordersテーブルを引き続き使用します。この記事の例を実行する前に、次のコードを実行して、不要なインデックスをいくつか削除してください。
DROP INDEX IF EXISTS idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX IF EXISTS idx_unc_od_oid_i_cid_eid ON dbo.Orders;
このテーブルに残しておく必要があるインデックスは、idx_cl_od(orderdateをキーとしてクラスター化)とPK_Orders(orderidをキーとして非クラスター化)の2つだけです。
並列処理戦略
SQL Serverは、さまざまなグループ化および集約戦略(事前に順序付けられたStream Aggregate、Sort + Stream Aggregate、Hash Aggregate)から選択する必要があるだけでなく、シリアルプランとパラレルプランのどちらを使用するかを選択する必要もあります。実際、複数の異なる並列処理戦略から選択できます。 SQL Serverは、さまざまな条件下で1つの戦略を他の戦略よりも優先する最適化しきい値をもたらす原価計算ロジックを使用します。シリーズの前のパートでは、SQLServerがシリアルプランで使用する原価計算ロジックについてすでに詳しく説明しました。このセクションでは、SQLServerがグループ化と集約を処理するために使用できるいくつかの並列処理戦略を紹介します。最初は、原価計算ロジックの詳細には触れず、利用可能なオプションについて説明します。記事の後半で、原価計算式がどのように機能するか、および原価計算のDOPと呼ばれるこれらの式の重要な要素について説明します。
後で学習するように、SQL Serverは、並列プランのコスト計算式でマシン内の論理CPUの数を考慮に入れます。私の例では、特に断りのない限り、ターゲットシステムには8つの論理CPUがあると想定しています。私が提供する例を試してみたい場合は、私と同じプランとコスト値を取得するために、8つの論理CPUを搭載したマシンでもコードを実行する必要があります。マシンのCPU数が異なる場合は、次のように、コスト計算の目的で8個のCPUを搭載したマシンをエミュレートできます。
DBCC OPTIMIZER_WHATIF(CPUs、8);
このツールは公式に文書化およびサポートされていませんが、調査や学習の目的には非常に便利です。
サンプルデータベースのOrdersテーブルには、1から1,000,000の範囲の注文IDを持つ1,000,000行があります。グループ化と集約のための3つの異なる並列処理戦略を示すために、注文IDが300001(700,000一致)以上の注文をフィルタリングし、3つの異なる方法でデータをグループ化します(custid [フィルタリング前の20,000グループ]、 empid [500グループ]、およびshipperid [5グループ])で、グループあたりの注文数を計算します。
次のコードを使用して、グループ化されたクエリをサポートするインデックスを作成します。
CREATE INDEX idx_oid_i_eid ON dbo.Orders(orderid)INCLUDE(empid); CREATE INDEX idx_oid_i_sid ON dbo.Orders(orderid)INCLUDE(shipperid); CREATE INDEX idx_oid_i_cid ON dbo.Orders(orderid)INCLUDE(custid); pre>次のクエリは、前述のフィルタリングとグループ化を実装します。
-クエリ1:シリアルSELECT custid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =300001GROUP BY custidOPTION(MAXDOP 1); -クエリ2:並列、ローカル/グローバルではないSELECT custid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =300001GROUP BY custid; -クエリ3:ローカル並列グローバル並列SELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =300001GROUP BY empid; -クエリ4:ローカルパラレルグローバルシリアルSELECT shipperid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =300001GROUP BY shipperid;クエリ1とクエリ2は同じであり(どちらもcustidでグループ化されています)、前者のみがシリアルプランを強制し、後者は8つのCPUを搭載したマシンでパラレルプランを取得することに注意してください。これらの2つの例を使用して、同じクエリのシリアル戦略とパラレル戦略を比較します。
図1は、4つのクエリすべての推定計画を示しています。
図1:並列処理戦略
今のところ、図に示されているコスト値と、コスト計算のDOPという用語の言及について心配する必要はありません。それらについては後で説明します。まず、戦略とその違いを理解することに焦点を当てます。
クエリ1のシリアルプランで使用される戦略は、シリーズの前のパートでおなじみのはずです。プランは、前に作成したカバーリングインデックスのシークを使用して、関連する注文をフィルタリングします。次に、グループ化および集約される推定行数を使用して、オプティマイザーは、ソート+ストリーム集約戦略よりもハッシュ集約戦略を優先します。
クエリ2の計画では、1つの集計演算子のみを使用する単純な並列処理戦略を使用しています。並列インデックスシーク演算子は、ラウンドロビン方式で行のパケットをさまざまなスレッドに配布します。行の各パケットには、複数の個別の顧客IDを含めることができます。単一の集計演算子が正しい最終グループ数を計算できるようにするには、同じグループに属するすべての行を同じスレッドで処理する必要があります。このため、並列処理(Repartition Streams)交換演算子を使用して、グループ化セット(custid)によってストリームを再パーティション化します。最後に、Parallelism(Gather Streams)交換演算子を使用して、複数のスレッドから結果行の単一のストリームにストリームを収集します。
クエリ3とクエリ4の計画では、より複雑な並列処理戦略を採用しています。計画は、並列のインデックスシーク演算子が行のパケットを異なるスレッドに配布するクエリ2の計画と同様に開始されます。次に、集約作業は2つのステップで実行されます。1つの集約オペレーターが現在のスレッドの行をローカルにグループ化して集約し(partialagg1004結果メンバーに注意)、2番目の集約オペレーターがローカル集約の結果をグローバルにグループ化して集約します(globalagg1005に注意)。結果メンバー)。ローカルとグローバルの2つの集約ステップのそれぞれで、シリーズの前半で説明した集約アルゴリズムのいずれかを使用できます。クエリ3とクエリ4の両方の計画は、ローカルのハッシュアグリゲートから始まり、グローバルなソート+ストリームアグリゲートに進みます。 2つの違いは、前者は両方のステップで並列処理を使用し(したがって、2つの間でRepartition Streams交換が使用され、グローバルアグリゲートの後にGather Streams交換が使用されます)、後者は並列ゾーンとグローバルでローカルアグリゲートを処理することです。シリアルゾーンで集約します(したがって、2つの間でGather Streams交換が使用されます)。
クエリの最適化全般、具体的には並列処理について調査する場合は、さまざまな最適化の側面を制御してその効果を確認できるツールに精通しているとよいでしょう。シリアル計画を強制する方法(MAXDOP 1ヒントを使用)、およびコスト計算の目的で特定の数の論理CPU(DBCC OPTIMIZER_WHATIF、CPUオプション付き)を持つ環境をエミュレートする方法を既に知っています。もう1つの便利なツールは、並列処理を最大化するクエリヒントENABLE_PARALLEL_PLAN_PREFERENCE(SQL Server 2016 SP1 CU2で導入)です。これが意味するのは、クエリで並列プランがサポートされている場合、並列処理できるプランのすべての部分で、無料であるかのように並列処理が優先されるということです。たとえば、図1で、クエリ4のプランは、デフォルトでシリアルゾーンのローカルアグリゲートとパラレルゾーンのグローバルアグリゲートを処理することに注意してください。これは同じクエリですが、今回はENABLE_PARALLEL_PLAN_PREFERENCEクエリヒントが適用されています(クエリ5と呼びます):
SELECT shipperid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =300001GROUP BY shipperidOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));クエリ5の計画を図2に示します。
図2:並列処理の最大化
今回は、ローカルアグリゲートとグローバルアグリゲートの両方が並列ゾーンで処理されることに注意してください。
シリアル/パラレルプランの選択
クエリの最適化中に、SQL Serverは複数の候補プランを作成し、作成したプランの中で最もコストの低いプランを選択することを思い出してください。用語コスト 見積もりによると、コストが最も低い候補プランは、全体として使用されるリソースの量が最も少ないプランではなく、実行時間が最も短いプランであると想定されているため、は少し誤称です。たとえば、シリアル候補プランと同じクエリに対して生成されたパラレルプランの間では、スレッドを同期する交換演算子(分散、再パーティション化、ストリームの収集)を使用する必要があるため、パラレルプランはより多くのリソースを使用する可能性があります。ただし、並列プランが実行を完了するのに必要な時間がシリアルプランよりも短いためには、複数のスレッドで作業を行うことによって達成される節約は、交換オペレーターによって行われる余分な作業を上回る必要があります。そして、これは、並列処理が含まれる場合にSQLServerが使用する原価計算式に反映される必要があります。正確に行うのは簡単な作業ではありません!
並列プランのコストを優先するには、シリアルプランのコストよりも低くする必要があることに加えて、代替のシリアルプランのコストは、並列処理のコストしきい値以上である必要があります。 。これは、デフォルトで5に設定されているサーバー構成オプションであり、かなり低コストのクエリが並列処理で処理されるのを防ぎます。ここでの考え方は、多数の小さなクエリを含むシステムは、スレッドの同期に多くのリソースを浪費するのではなく、シリアルプランを使用することで全体的にメリットが大きくなるということです。マシンのマルチCPUリソースを効率的に利用して、シリアルプランを同時に実行する複数のクエリを引き続き実行できます。実際、多くのSQL Serverプロフェッショナルは、並列処理のコストしきい値をデフォルトの5からより高い値に上げることを好みます。かなり少数の大きなクエリを同時に実行するシステムは、並列プランを使用することではるかに多くのメリットが得られます。
要約すると、SQL Serverがシリアルの代替案よりも並列プランを優先するためには、シリアルプランのコストは少なくとも並列処理のコストしきい値である必要があり、並列プランのコストはシリアルプランのコストよりも低い必要があります(潜在的に実行時間の短縮)。
実際の原価計算式の詳細に入る前に、シリアルプランとパラレルプランのどちらかを選択するさまざまなシナリオを例を挙げて説明します。例を試してみたい場合は、システムが私のようなクエリコストを取得するために8つの論理CPUを想定していることを確認してください。
次のクエリを検討してください(これらをクエリ6およびクエリ7と呼びます):
-クエリ6:シリアルSELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =400001GROUP BY empid; -クエリ7:強制並列SELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =400001GROUP BY empidOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));これらのクエリの計画を図3に示します。
図3:シリアルコスト<並列処理のコストしきい値、並列コスト<シリアルコスト
ここで、[強制]並列プランのコストは、シリアルプランのコストよりも低くなります。ただし、シリアルプランのコストは並列処理のデフォルトのコストしきい値である5よりも低いため、SQLServerはデフォルトでシリアルプランを選択しました。
次のクエリを検討してください(これらをクエリ8およびクエリ9と呼びます):
-クエリ8:並列SELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =300001GROUP BY empid; -クエリ9:強制シリアルSELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =300001GROUP BY empidOPTION(MAXDOP 1);これらのクエリの計画を図4に示します。
図4:シリアルコスト> =並列処理のコストしきい値、並列コスト<シリアルコスト
ここで、[強制]シリアルプランのコストは並列処理のコストしきい値以上であり、並列プランのコストはシリアルプランのコストよりも低いため、SQLServerはデフォルトで並列プランを選択しました。
次のクエリを検討してください(クエリ10およびクエリ11と呼びます):
-クエリ10:シリアルSELECT * FROM dbo.OrdersWHERE orderid> =100000; -クエリ11:強制並列SELECT * FROM dbo.OrdersWHERE orderid> =100000OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));これらのクエリの計画を図5に示します。
図5:シリアルコスト> =並列処理のコストしきい値、並列コスト>=シリアルコスト
ここで、シリアルプランのコストは、並列処理のコストしきい値以上です。ただし、シリアルプランのコストは[強制]パラレルプランのコストよりも低いため、SQLServerはデフォルトでシリアルプランを選択しました。
ENABLE_PARALLEL_PLAN_PREFERENCEヒントを使用して並列処理を最大化することについて、知っておく必要のあるもう1つのことがあります。 SQL Serverが並列プランを使用できるようにするには、残差述語、並べ替え、集計などの並列処理イネーブラーが必要です。残りの述部がなく、他の並列処理イネーブラーがない、インデックススキャンまたはインデックスシークのみを適用するプランは、シリアルプランで処理されます。例として次のクエリを考えてみましょう(これらをクエリ12およびクエリ13と呼びます):
-クエリ12SELECT* FROM dbo.OrdersOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE')); --クエリ13SELECT* FROM dbo.OrdersWHERE orderid> =100000OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));これらのクエリの計画を図6に示します。
図6:並列処理イネーブラー
並列処理イネーブラーがないため、ヒントにもかかわらず、クエリ12はシリアルプランを取得します。残りの述語が含まれているため、クエリ13は並列プランを取得します。
原価計算のためのDOPの計算とテスト
マイクロソフトは、シリアルプランのコストが実行時間の短縮を反映するよりもパラレルプランのコストを低くするために、原価計算式を調整する必要がありました。その逆も同様です。考えられるアイデアの1つは、シリアルオペレーターのCPUコストを取得し、それをマシン内の論理CPUの数で割って、パラレルオペレーターのCPUコストを算出することでした。マシン内のCPUの論理数は、クエリの並列度、つまりDOP(プランの並列ゾーンで使用できるスレッドの数)を決定する主な要因です。ここでの単純な考え方は、オペレーターが1つのスレッドを使用するときに完了するのにT時間単位を要し、クエリの並列度がDである場合、Dスレッドを使用するときにオペレーターのT/D時間が完了するということです。実際には、物事はそれほど単純ではありません。たとえば、通常、1つだけでなく複数のクエリを同時に実行している場合、1つのクエリでマシンのすべてのCPUリソースを取得することはできません。そこで、Microsoftは原価計算の並列度のアイデアを思いつきました。 (要するに、原価計算のためのDOP)。この測定値は通常、マシン内の論理CPUの数よりも少なく、並列オペレーターのCPUコストを計算するためにシリアルオペレーターのCPUコストを割った係数です。
通常、原価計算のDOPは、整数除算を使用して、論理CPUの数を2で割ったものとして計算されます。ただし、例外があります。 CPUの数が2または3の場合、原価計算のDOPは2に設定されます。4つ以上のCPUの場合、原価計算のDOPは整数除算を使用して#CPU/2に設定されます。これは、マシンで使用可能なメモリの量に応じて、特定の最大値までです。最大4,096MBのメモリを搭載したマシンでは、原価計算の最大DOPは8です。 4,096 MBを超える場合、原価計算の最大DOPは32です。
このロジックをテストするには、次のようにCPUオプションを指定してDBCCOPTIMIZER_WHATIFを使用して必要な数の論理CPUをエミュレートする方法をすでに知っています。
DBCC OPTIMIZER_WHATIF(CPUs、8);MemoryMBsオプションで同じコマンドを使用すると、次のようにMB単位で必要な量のメモリをエミュレートできます。
DBCC OPTIMIZER_WHATIF(MemoryMBs、16384);次のコードを使用して、エミュレートされたオプションの既存のステータスを確認します。
DBCC TRACEON(3604); DBCC OPTIMIZER_WHATIF(ステータス); DBCC TRACEOFF(3604);次のコードを使用して、すべてのオプションをリセットします。
DBCC OPTIMIZER_WHATIF(ResetAll);論理CPUの入力数とメモリの量に基づいて原価計算のDOPを計算するために使用できるT-SQLクエリは次のとおりです。
DECLARE @NumCPUs AS INT =8、@ MemoryMBs AS INT =16384; SELECT CASE WHEN @NumCPUs =1 THEN 1 WHEN @NumCPUs <=3 THEN 2 WHEN @NumCPUs> =4 THEN(SELECT MIN(n)FROM(VALUES(@NumCPUs / 2)、(MaxDOP4C))AS D2(n)) END AS DOP4CFROM(VALUES(CASE WHEN @MemoryMBs <=4096 THEN 8 ELSE 32 END))AS D1(MaxDOP4C);指定された入力値で、このクエリは4を返します。
表1に、マシンのCPUの論理数とメモリの量に基づいて取得するコストのDOPの詳細を示します。
| #CPUs | MemoryMBs <=4096 | の場合の原価計算のDOPMemoryMBs>4096の場合の原価計算のDOP |
|---|---|---|
| 1 | 1 | 1 |
| 2-5 | 2 | 2 |
| 6-7 | 3 | 3 |
| 8-9 | 4 | 4 |
| 10-11 | 5 | 5 |
| 12-13 | 6 | 6 |
| 14-15 | 7 | 7 |
| 16-17 | 8 | 8 |
| 18-19 | 8 | 9 |
| 20-21 | 8 | 10 |
| 22-23 | 8 | 11 |
| 24-25 | 8 | 12 |
| 26-27 | 8 | 13 |
| 28-29 | 8 | 14 |
| 30-31 | 8 | 15 |
| 32-33 | 8 | 16 |
| 34-35 | 8 | 17 |
| 36-37 | 8 | 18 |
| 38-39 | 8 | 19 |
| 40-41 | 8 | 20 |
| 42-43 | 8 | 21 |
| 44-45 | 8 | 22 |
| 46-47 | 8 | 23 |
| 48-49 | 8 | 24 |
| 50-51 | 8 | 25 |
| 52-53 | 8 | 26 |
| 54-55 | 8 | 27 |
| 56-57 | 8 | 28 |
| 58-59 | 8 | 29 |
| 60-61 | 8 | 30 |
| 62-63 | 8 | 31 |
| > =64 | 8 | 32 |
表1:原価計算のDOP
例として、前に示したクエリ1とクエリ2をもう一度見てみましょう。
-クエリ1:強制シリアルSELECT custid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =300001GROUP BY custidOPTION(MAXDOP 1); -クエリ2:当然並列SELECT custid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =300001GROUP BY custid;
これらのクエリの計画を図7に示します。
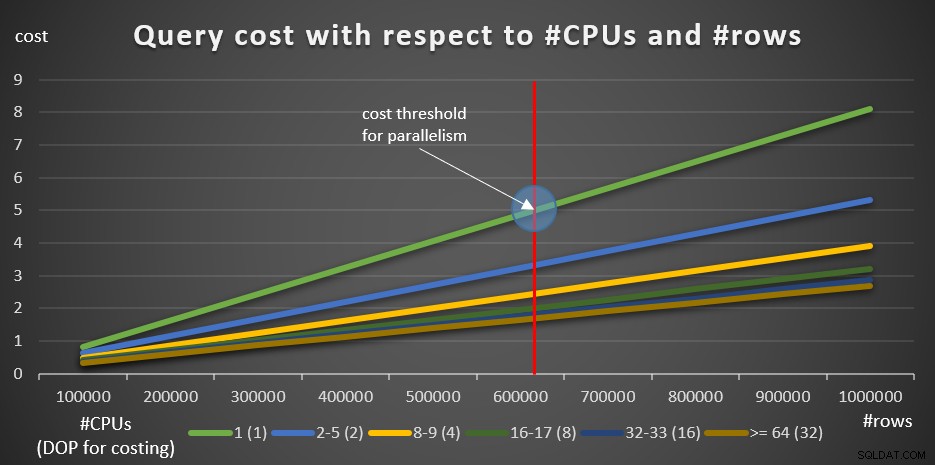 図7:DOP for原価計算
図7:DOP for原価計算
クエリ1はシリアルプランを強制しますが、クエリ2は私の環境でパラレルプランを取得します(8つの論理CPUと16,384 MBのメモリをエミュレートします)。これは、私の環境での原価計算のDOPが4であることを意味します。前述のように、並列オペレーターのCPUコストは、シリアルオペレーターのCPUコストを原価計算のDOPで割ったものとして計算されます。これは、並行して実行されるIndexSeek演算子とHashAggregate演算子を使用した並列計画の場合に実際に当てはまることがわかります。
交換事業者のコストについては、初期費用と行ごとの一定の費用で構成されており、簡単にリバースエンジニアリングできます。
ここで使用されている単純な並列グループ化および集約戦略では、シリアルプランとパラレルプランのカーディナリティ推定値が同じであることに注意してください。これは、集約演算子が1つしか使用されていないためです。後で、ローカル/グローバル戦略を使用すると状況が異なることがわかります。
次のクエリは、論理CPUの数と関連する行の数がクエリコストに与える影響を説明するのに役立ちます(10クエリ、100K行の増分):
SELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =900001GROUP BY empid; SELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =800001GROUP BY empid; SELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =700001GROUP BY empid; SELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =600001GROUP BY empid; SELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =500001GROUP BY empid; SELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =400001GROUP BY empid; SELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =300001GROUP BY empid; SELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =200001GROUP BY empid; SELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =100001GROUP BY empid; SELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =000001GROUP BY empid;
図8に結果を示します。
図8:クエリコスト#CPUと#rowsに関して
緑の線は、シリアルプランを使用したさまざまなクエリ(さまざまな行数)のコストを表しています。他の線は、論理CPUの数が異なる並列プランのコストと、コストのそれぞれのDOPを表しています。赤い線は、シリアルクエリのコストが5(並列処理設定のデフォルトのコストしきい値)になるポイントを表します。このポイントの左側(グループ化および集約される行が少ない)では、通常、オプティマイザーは並列プランを考慮しません。並列処理のコストしきい値を下回る並列プランのコストを調査できるようにするには、次の2つのいずれかを実行できます。 1つのオプションは、クエリヒントENABLE_PARALLEL_PLAN_PREFERENCEを使用することですが、念のため、このオプションは、強制するのではなく、並列処理を最大化します。それが望ましい効果ではない場合は、次のように、並列処理のコストしきい値を無効にすることができます。
EXEC sp_configure'詳細オプションを表示'、1;再構成; EXEC sp_configure'並列処理のコストしきい値'、0; EXEC sp_configure'詳細オプションを表示'、0;再構成;
明らかに、これは本番システムでは賢明な動きではありませんが、研究目的には完全に役立ちます。これが、図8のグラフの情報を作成するために私が行ったことです。
10万行から始めて、10万の増分を追加すると、すべてのグラフは、並列処理のコストしきい値が要因ではなかったことを示しているようです。並列プランが常に優先されていました。これは、クエリと関連する行数の場合に当てはまります。ただし、次の5つのクエリを使用して、10Kから開始し、10Kずつ増加して、行数を減らしてみてください(ここでも、並列処理のコストしきい値を無効のままにします):
SELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =990001GROUP BY empid; SELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =980001GROUP BY empid; SELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =970001GROUP BY empid; SELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =960001GROUP BY empid; SELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =950001GROUP BY empid;
図9は、シリアルプランとパラレルプランの両方でのクエリコストを示しています(4つのCPUをエミュレートし、2つのコストを計算するためのDOP)。
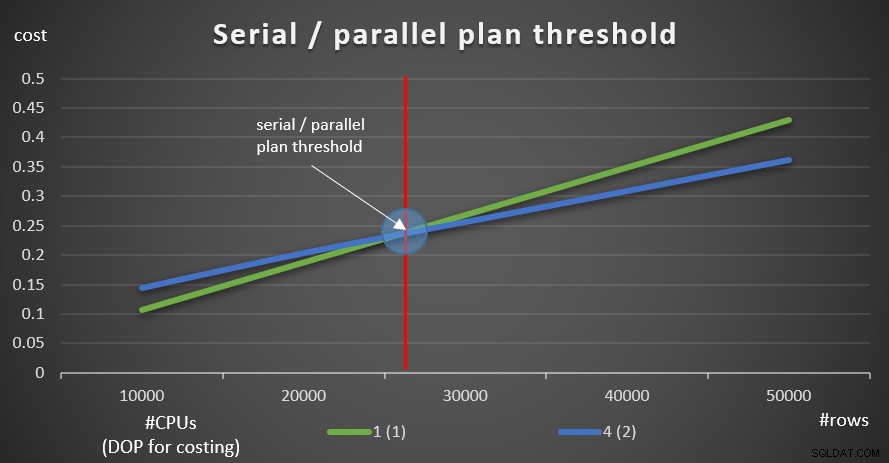 図9:シリアル/並列プランのしきい値
図9:シリアル/並列プランのしきい値
ご覧のとおり、最適化のしきい値には、シリアルプランが優先され、それを超えるとパラレルプランが優先されます。前述のように、並列処理のコストしきい値をデフォルト値の5以上に維持する通常のシステムでは、有効なしきい値はこのグラフよりも高くなります。
SQL Serverが単純なグループ化と集約の並列処理戦略を選択する場合、シリアルプランとパラレルプランのカーディナリティの見積もりは同じです。問題は、SQLServerがローカル/グローバル並列処理戦略のカーディナリティ推定をどのように処理するかです。
これを理解するために、前の例のクエリ3とクエリ4を使用します。
-クエリ3:ローカルパラレルグローバルパラレルSELECT empid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =300001GROUP BY empid; -クエリ4:ローカルパラレルグローバルシリアルSELECT shipperid、COUNT(*)AS numordersFROM dbo.OrdersWHERE orderid> =300001GROUP BY shipperid;
8つの論理CPUと4の原価計算値の有効なDOPを備えたシステムで、図10に示す計画を取得しました。
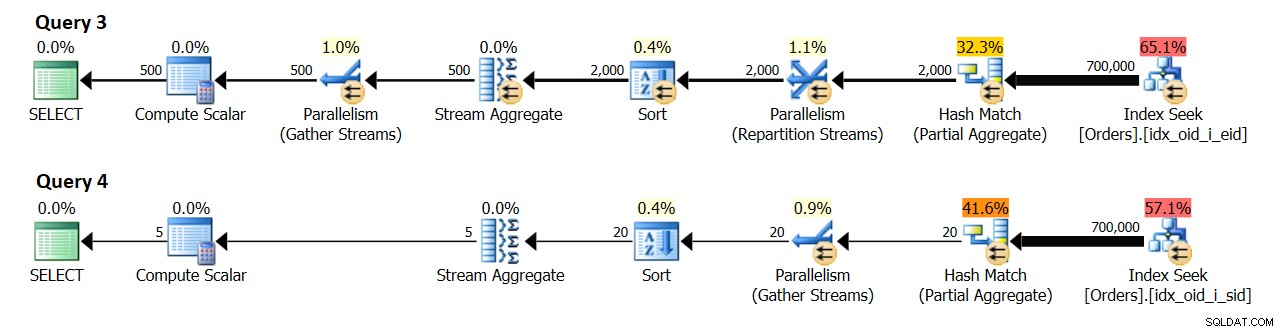 図10:カーディナリティの見積もり
図10:カーディナリティの見積もり
クエリ3は、注文をempidでグループ化します。最終的には500の異なる従業員グループが見込まれます。
クエリ4は、shipperidごとに注文をグループ化します。最終的には、5つの異なる荷送人グループが予想されます。
不思議なことに、ローカルアグリゲートによって生成されたグループの数のカーディナリティの見積もりは、{各スレッドによって期待される個別のグループの数}*{原価計算のDOP}のようです。実際には、カウントされるのは主に論理CPUの数に基づく実行用のDOP(別名、単にDOP)であるため、この数は通常2倍になることがわかります。 CPUオプションを指定したDBCCOPTIMIZER_WHATIFコマンドはコスト計算のDOPの計算に影響を与えるため、この部分を調査目的でエミュレートするのは少し難しいですが、実行のDOPは、SQLServerインスタンスが認識する実際の論理CPUの数を超えることはありません。この数は、基本的にSQLServerが開始するスケジューラーの数に基づいています。 できます SQLServerが-P{#schedulers}起動パラメーターを使用して開始するスケジューラーの数を制御しますが、これはセッションオプションに比べて少し積極的な調査ツールです。
いずれにせよ、リソースをエミュレートせずに、テストマシンには4つの論理CPUがあり、コスト2のDOPと実行4のDOPになります。私の環境では、クエリ3の計画のローカル集計は1,000の結果グループの見積もりを示しています(500 x 2)、および実際の2,000(500 x 4)。同様に、クエリ4の計画のローカル集計では、10個の結果グループ(5 x 2)の推定値と、20個の実際の結果(5 x 4)が示されています。
実験が終わったら、クリーンアップのために次のコードを実行します。
-並列処理のコストしきい値をデフォルトのEXECに設定しますsp_configure'詳細オプションを表示'、1;再構成; EXEC sp_configure'並列処理のコストしきい値'、5; EXEC sp_configure'詳細オプションを表示'、0; RECONFIGURE;GO-OPTIMIZER_WHATIFオプションをリセットしますDBCCOPTIMIZER_WHATIF(ResetAll); -インデックスの削除DROPINDEXidx_oid_i_sid ON dbo.Orders; DROP INDEX idx_oid_i_eid ON dbo.Orders; DROP INDEX idx_oid_i_cid ON dbo.Orders;
結論
この記事では、SQLServerがグループ化と集約を処理するために使用するいくつかの並列処理戦略について説明しました。並列計画を使用したクエリの最適化で理解する重要な概念は、原価計算の並列度(DOP)です。シリアルプランとパラレルプランの間のしきい値や、並列処理のコストしきい値の設定など、いくつかの最適化しきい値を示しました。ここで説明した概念のほとんどは、グループ化と集約に固有のものではなく、SQLServer全般の並列プランの考慮事項にも同様に適用できます。来月は、クエリの書き換えによる最適化について説明することで、シリーズを続けます。