この記事は、データのグループ化と集約の最適化しきい値に関するシリーズの3番目です。パート1では、事前注文されたStreamAggregateアルゴリズムについて説明しました。パート2では、事前に順序付けされていない並べ替え+ストリーム集計アルゴリズムについて説明しました。このパートでは、Hash Match(Aggregate)アルゴリズムについて説明します。これを、単にHashAggregateと呼びます。また、パート1、パート2、およびパート3で取り上げたアルゴリズムの概要と比較も提供します。
シリーズの以前の記事で使用したのと同じPerformanceV3というサンプルデータベースを使用します。記事の例を実行する前に、まず次のコードを実行して、不要なインデックスをいくつか削除するようにしてください。
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
このテーブルに残しておく必要があるインデックスは、idx_cl_od(orderdateをキーとしてクラスター化)とPK_Orders(orderidをキーとして非クラスター化)の2つだけです。
ハッシュアグリゲート
Hash Aggregateアルゴリズムは、内部で選択されたハッシュ関数に基づいて、グループをハッシュテーブルに編成します。 Stream Aggregateアルゴリズムとは異なり、グループ順に行を消費する必要はありません。例として、次のクエリ(クエリ1と呼びます)を考えてみましょう(ハッシュ集計とシリアルプランを強制する):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1);
図1は、クエリ1の計画を示しています。
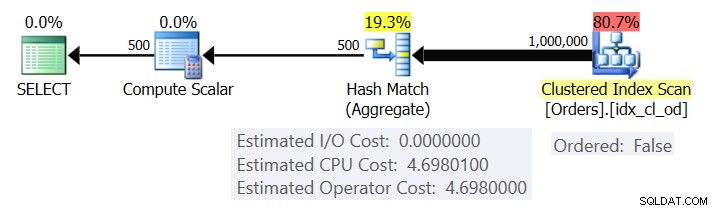
図1:クエリ1の計画
プランは、Ordered:Falseプロパティを使用してクラスター化インデックスから行をスキャンします(インデックスキーで順序付けられた行を配信するためにスキャンは必要ありません)。通常、オプティマイザは最も狭いカバーインデックスをスキャンすることを好みます。この場合、これはたまたまクラスター化されたインデックスです。計画では、グループ化された列と集計を使用してハッシュテーブルを作成します。このクエリは、INT型のCOUNT集計を要求します。プランは実際にはそれをBIGINT型の値として計算するため、Compute Scalar演算子を使用して、INTに暗黙の変換を適用します。
Microsoftは、使用するハッシュアルゴリズムを公に共有していません。これは非常に独自の技術です。それでも、概念を説明するために、SQL Serverが上記のクエリに%250(モジュロ250)ハッシュ関数を使用するとします。行を処理する前に、ハッシュテーブルにはハッシュ関数の250の可能な結果(0から249)を表す250のバケットがあります。 SQL Serverは各行を処理するときに、ハッシュ関数
orderid empid ------- ----- 320 3 30 5 660 253 820 3 850 1 1000 255 700 3 1240 253 350 4 400 255
図2は、ハッシュテーブルの3つの状態を示しています。行が処理される前、最初の5行が処理された後、最初の10行が処理された後です。リンクリストの各アイテムはタプル(empid、COUNT(*))を保持します。
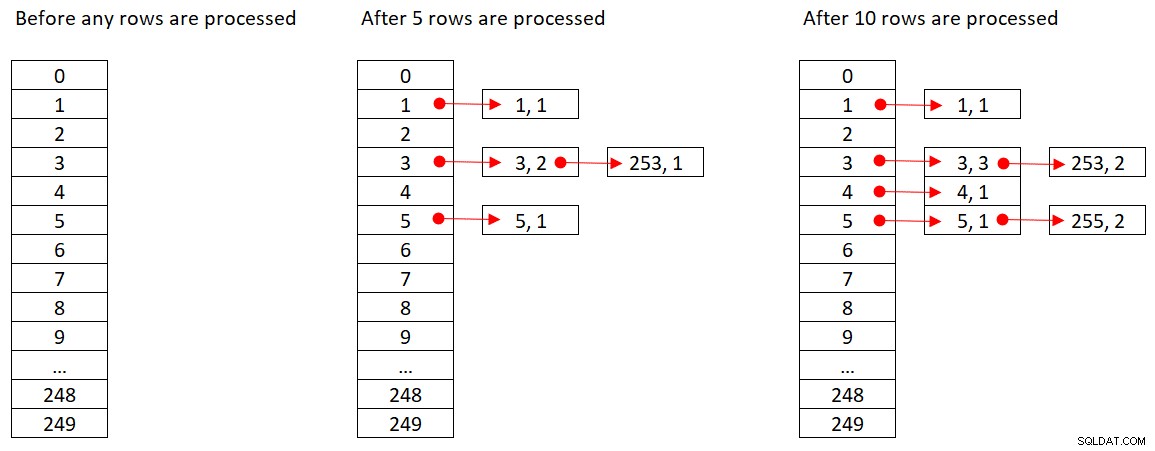
図2:ハッシュテーブルの状態
Hash Aggregateオペレーターがすべての入力行の消費を終了すると、ハッシュテーブルには、集計の最終状態を持つすべてのグループが含まれます。
Sort演算子と同様に、Hash Aggregate演算子にはメモリの付与が必要であり、メモリが不足した場合は、tempdbにスピルする必要があります。ただし、並べ替えには、並べ替える行の数に比例するメモリ許可が必要ですが、ハッシュには、グループの数に比例するメモリ許可が必要です。したがって、特にグループ化セットの密度が高い場合(グループの数が少ない場合)、このアルゴリズムは、明示的な並べ替えが必要な場合よりも大幅に少ないメモリを必要とします。
次の2つのクエリ(クエリ1とクエリ2と呼びます)について考えてみます。
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1); SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (ORDER GROUP, MAXDOP 1);
図3は、これらのクエリのメモリ付与を比較しています。

図3:クエリ1とクエリ2の計画
2つの場合のメモリ付与の大きな違いに注意してください。
Hash Aggregateオペレーターのコストについては、図1に戻ると、I / Oコストはなく、CPUコストのみであることに注意してください。次に、シリーズの前のパートで説明したのと同様の手法を使用して、CPUコスト計算式をリバースエンジニアリングしてみます。オペレーターのコストに影響を与える可能性のある要因は、入力行の数、出力グループの数、使用される集計関数、およびグループ化する対象(グループ化セットのカーディナリティ、使用されるデータ型)です。
このオペレーターには、ハッシュテーブルの作成に備えて初期費用がかかることが予想されます。また、行とグループの数に関して線形にスケーリングすることも期待できます。それは確かに私が見つけたものです。ただし、Stream Aggregate演算子とSort演算子の両方のコストは、グループ化する対象の影響を受けませんが、Hash Aggregate演算子のコストは、グループ化セットのカーディナリティと使用されるデータ型の両方の観点から影響を受けるようです。
グループ化セットのカーディナリティがオペレーターのコストに影響することを確認するには、次のクエリ(クエリ3およびクエリ4と呼びます)の計画でハッシュ集計オペレーターのCPUコストを確認します。
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 50 AS grp1, orderid % 20 AS grp2, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 50, orderid % 20 OPTION(HASH GROUP, MAXDOP 1);
もちろん、どちらの場合も、入力行と出力グループの推定数が同じであることを確認する必要があります。これらのクエリの推定計画を図4に示します。
図4:クエリ3とクエリ4の計画
ご覧のとおり、Hash Aggregate演算子のCPUコストは、1つの整数列でグループ化する場合は0.16903、2つの整数列でグループ化する場合は0.174016であり、他はすべて同じです。これは、グループ化セットのカーディナリティが実際にコストに影響を与えることを意味します。
グループ化された要素のデータ型がコストに影響するかどうかについては、次のクエリを使用してこれを確認しました(クエリ5、クエリ6、クエリ7と呼びます)。
SELECT CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT) AS grp,
MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT)
OPTION(HASH GROUP, MAXDOP 1);
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY orderid % 1000
OPTION(HASH GROUP, MAXDOP 1);
SELECT CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT) AS grp,
MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT)
OPTION(HASH GROUP, MAXDOP 1); 3つのクエリすべてのプランには、入力行と出力グループの推定数が同じですが、すべての推定CPUコスト(0.121766、0.16903、0.171716)が異なるため、使用されるデータ型はコストに影響します。
集計関数の種類もコストに影響を与えるようです。たとえば、次の2つのクエリ(クエリ8とクエリ9と呼びます)について考えてみます。
SELECT orderid % 1000 AS grp, COUNT(*) AS numorders FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1);
クエリ8の計画でのハッシュアグリゲートの推定CPUコストは0.166344であり、クエリ9では0.16903です。
グループ化セットのカーディナリティ、データ型、および使用される集計関数がコストにどのように影響するかを正確に把握することは、興味深い演習になる可能性があります。私は原価計算のこの側面を追求しませんでした。したがって、クエリのグループ化セットと集計関数を選択した後、原価計算式をリバースエンジニアリングできます。たとえば、単一の整数列でグループ化してMAX(orderdate)集計を返す場合に、HashAggregate演算子のCPUコスト計算式をリバースエンジニアリングしてみましょう。式は次のようになります。
オペレーターのCPUコスト=<起動コスト>+@numrows*<行あたりのコスト>+@numgroups*<グループあたりのコスト>シリーズの以前の記事で示した手法を使用して、次のリバースエンジニアリング式を取得しました。
オペレーターのCPUコスト=0.01749+ @numrows * 0.00000667857 + @numgroups * 0.0000177087次のクエリを使用して、数式の正確さを確認できます。
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 2000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 2000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 3000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 3000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 6000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 6000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 5000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 5000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(HASH GROUP, MAXDOP 1);
次の結果が得られます:
numrows numgroups predictedcost estimatedcost ----------- ----------- -------------- -------------- 100000 1000 0.703315 0.703316 100000 2000 0.721023 0.721024 200000 3000 1.40659 1.40659 200000 6000 1.45972 1.45972 500000 5000 3.44558 3.44558 500000 10000 3.53412 3.53412
公式は的を射ているようです。
原価計算の概要と比較
これで、利用可能な3つの戦略(事前注文されたStream Aggregate、Sort + Stream Aggregate、およびHashAggregate)の原価計算式ができました。次の表は、3つのアルゴリズムの原価計算特性をまとめて比較したものです。
| 事前注文されたストリームアグリゲート | 並べ替え+ストリーム集計 | ハッシュアグリゲート | |
| 式 | @numrows * 0.0000006 + @numgroups * 0.0000005 | 0.0112613 + 行数が少ない: 9.99127891201865E-05 + @numrows * LOG(@numrows)* 2.25061348918698E-06 多数の行: 1.35166186417734E-04 + @numrows * LOG(@numrows)* 6.62193536908588E-06 + @numrows * 0.0000006 + @numgroups * 0.0000005 | 0.017749 + @numrows * 0.00000667857 + @numgroups * 0.0000177087
*単一の整数列でグループ化し、MAX( |
| スケーリング | 線形 | n log n | 線形 |
| 起動I/Oコスト | なし | 0.0112613 | なし |
| 起動CPUコスト | なし | 〜0.0001 | 0.017749 |
これらの式に従って、図5は、例として500の固定数のグループを使用して、各戦略がさまざまな数の入力行に対してスケーリングする方法を示しています。
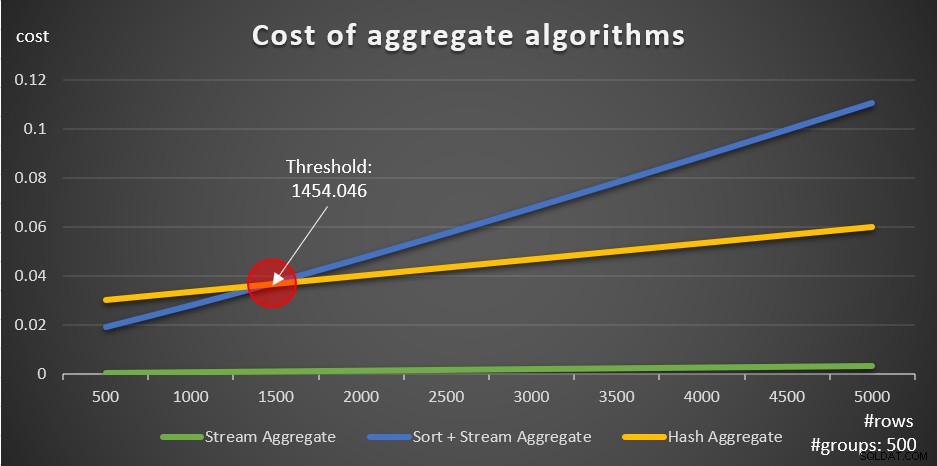
図5:集約アルゴリズムのコスト
データが事前に並べ替えられている場合(たとえば、カバーインデックスで)、関係する行の数に関係なく、事前に並べ替えられたStreamAggregate戦略が最適なオプションであることがはっきりとわかります。たとえば、Ordersテーブルをクエリして、各従業員の最大注文日を計算する必要があるとします。次のカバーインデックスを作成します:
CREATE INDEX idx_eid_od ON dbo.Orders(empid, orderdate);
行数が異なる(10,000、20,000、30,000、40,000、50,000)Ordersテーブルをエミュレートする5つのクエリを次に示します。
SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (30000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (40000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (50000) * FROM dbo.Orders) AS D GROUP BY empid;
図6は、これらのクエリの計画を示しています。
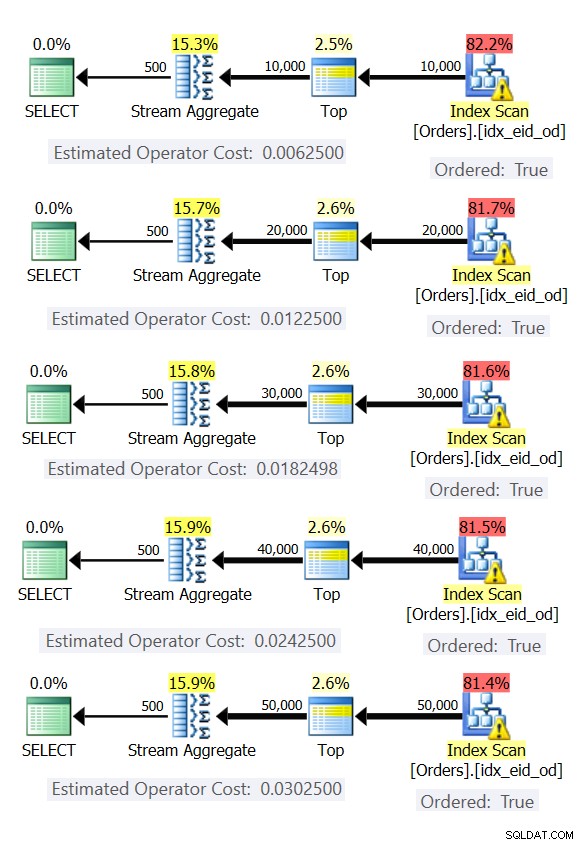
図6:事前注文されたStreamAggregate戦略を使用した計画
いずれの場合も、プランはカバーリングインデックスの順序付きスキャンを実行し、明示的な並べ替えを必要とせずにStreamAggregate演算子を適用します。
次のコードを使用して、この例で作成したインデックスを削除します。
DROP INDEX idx_eid_od ON dbo.Orders;
図5のグラフについて注意すべきもう1つの重要な点は、データが事前注文されていない場合に何が起こるかです。これは、カバーインデックスが設定されていない場合や、ベース列ではなく操作された式でグループ化した場合に発生します。最適化のしきい値(この場合は1454.046行)があり、それを下回るとソート+ストリーム集約戦略のコストが低くなり、それを超えるとハッシュ集約戦略のコストが低くなります。これは、前者のハッシュは起動コストが低くなりますが、n log n方式でスケーリングするのに対し、後者は起動コストが高くなりますが、線形にスケーリングするという事実と関係があります。これにより、入力行の数が少ない場合は前者が優先されます。リバースエンジニアリングされた数式が正確である場合、次の2つのクエリ(クエリ10とクエリ11と呼びます)は異なる計画を取得する必要があります。
SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1454) * FROM dbo.Orders) AS D GROUP BY orderid % 500; SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1455) * FROM dbo.Orders) AS D GROUP BY orderid % 500;
これらのクエリの計画を図7に示します。
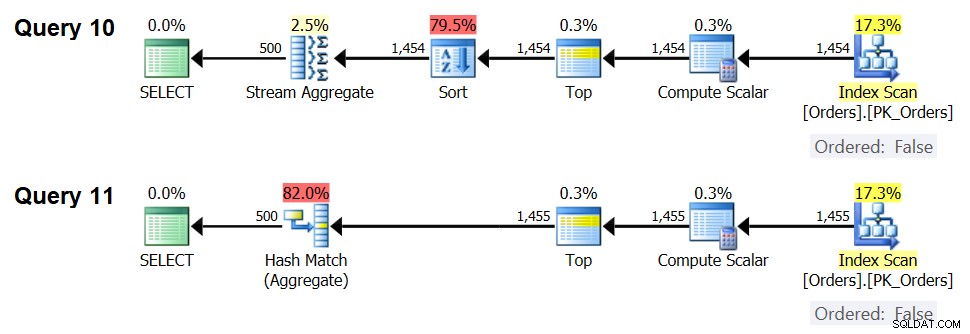
図7:クエリ10とクエリ11の計画
実際、1,454の入力行(最適化のしきい値を下回る)では、オプティマイザーは当然、クエリ10の並べ替え+ストリーム集計アルゴリズムを優先し、1,455の入力行(最適化のしきい値を超える)では、オプティマイザーは、クエリ11のハッシュ集計アルゴリズムを当然優先します。 。
アダプティブアグリゲートオペレーターの可能性
最適化しきい値のトリッキーな側面の1つは、ストアドプロシージャでパラメータに依存するクエリを使用する場合のパラメータスニッフィングの問題です。例として、次のストアドプロシージャについて考えてみます。
CREATE OR ALTER PROC dbo.EmpOrders @initialorderid AS INT AS SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= @initialorderid GROUP BY empid; GO
ストアドプロシージャクエリをサポートするには、次の最適なインデックスを作成します。
CREATE INDEX idx_oid_i_eid ON dbo.Orders(orderid) INCLUDE(empid);
クエリの範囲フィルターをサポートするためのキーとしてorderidを使用してインデックスを作成し、カバレッジ用にempidを含めました。これは、範囲フィルターをサポートし、フィルター処理された行がグループ化セットによって事前に並べ替えられるインデックスを実際に作成できない状況です。これは、オプティマイザがソート+ストリーム集約アルゴリズムとハッシュ集約アルゴリズムのどちらかを選択する必要があることを意味します。原価計算式に基づくと、最適化のしきい値は937〜938の入力行(たとえば、937.5行)です。
少数の一致(しきい値未満)を与える入力初期注文IDを使用して、ストアドプロシージャを最初に実行するとします。
EXEC dbo.EmpOrders @initialorderid = 999991;
SQL Serverは、Sort + Stream Aggregateアルゴリズムを使用するプランを作成し、プランをキャッシュします。後続の実行では、関係する行数に関係なく、キャッシュされたプランが再利用されます。たとえば、次の実行では、最適化のしきい値を超える一致が多数あります。
EXEC dbo.EmpOrders @initialorderid = 990001;
それでも、この実行には最適ではないという事実にもかかわらず、キャッシュされたプランを再利用します。これは典型的なパラメータスニッフィングの問題です。
SQL Server 2017には、適応クエリ処理機能が導入されています。この機能は、クエリの実行中にどの戦略を採用するかを決定することで、このような状況に対処するように設計されています。これらの改善の中には、実行中に計算された最適化しきい値に基づいてループアルゴリズムとハッシュアルゴリズムのどちらをアクティブにするかを決定する適応結合演算子があります。私たちの集約ストーリーは、実行中に、計算された最適化しきい値に基づいて、ソート+ストリーム集約戦略とハッシュ集約戦略のどちらかを選択する、同様の適応集約演算子を求めています。図8は、このアイデアに基づく疑似計画を示しています。
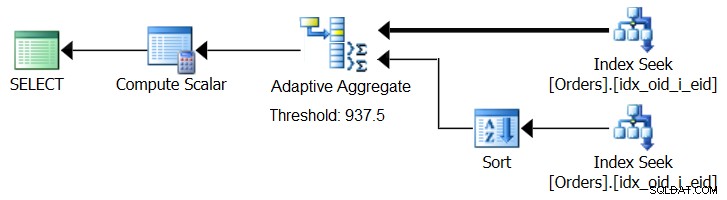
図8:アダプティブアグリゲート演算子を使用した疑似プラン
今のところ、そのような計画を立てるには、Microsoftペイントを使用する必要があります。ただし、適応型クエリ処理の概念は非常にスマートでうまく機能するため、将来的にこの分野でさらなる改善が見られると期待するのは合理的です。
次のコードを実行して、この例で作成したインデックスを削除します。
DROP INDEX idx_oid_i_eid ON dbo.Orders;
結論
この記事では、Hash Aggregateアルゴリズムのコストとスケーリングについて説明し、StreamAggregateおよびSort+StreamAggregate戦略と比較しました。ソート+ストリーム集約戦略とハッシュ集約戦略の間に存在する最適化しきい値について説明しました。入力行の数が少ない場合は前者が優先され、入力行の数が多い場合は後者が優先されます。また、すでに実装されているAdaptive Join演算子と同様に、Adaptive Aggregate演算子を追加して、パラメーターに依存するクエリを使用する際のパラメータースニッフィングの問題に対処できる可能性についても説明しました。来月は、並列処理の考慮事項とクエリの書き換えが必要なケースについて説明し、議論を続けます。