これは、数級数ジェネレータの課題に対するソリューションに関するシリーズの第3部です。パート1では、その場で行を生成するソリューションについて説明しました。パート2では、行を事前入力する物理ベーステーブルをクエリするソリューションについて説明しました。今月は、私たちの課題を処理するために使用できる魅力的なテクニックに焦点を当てますが、それはそれをはるかに超えた興味深いアプリケーションも持っています。この手法の正式な名前はわかりませんが、概念的には水平パーティションの削除と多少似ているため、非公式に水平単位の削除と呼びます。 技術。この手法には興味深いプラスのパフォーマンス上の利点がありますが、特定の条件下でパフォーマンスが低下する可能性がある場合に注意する必要のある警告もあります。
アイデアやコメントを共有してくれたAlanBurstein、Joe Obbish、Adam Machanic、Christopher Ford、Jeff Moden、Charlie、NoamGr、Kamil Kosno、Dave Mason、John Nelson#2、Ed Wagner、Michael Burbea、PaulWhiteに改めて感謝します。
tempdbでテストを行い、時間統計を有効にします:
SET NOCOUNT ON; USE tempdb; SET STATISTICS TIME ON;
初期のアイデア
水平単位の削除手法は、列の削除ロジック、または垂直単位の削除の代わりに使用できます。 以前に取り上げたソリューションのいくつかで信頼していたテクニック。テーブル式を使用した列除去ロジックの基本については、テーブル式の基礎、パート3 –派生テーブル、「列の射影とSELECT*に関する単語」の最適化に関する考慮事項を参照してください。
垂直単位除去手法の基本的な考え方は、列xとyを返すネストされたテーブル式があり、外部クエリが列xのみを参照している場合、クエリコンパイルプロセスは最初のクエリツリーからyを削除するため、プランが削除されるというものです。それを評価する必要はありません。これには、xのみでインデックスカバレッジを達成する、yが計算の結果である場合、yの基礎となる式をまったく評価する必要がないなど、最適化に関連するいくつかの肯定的な影響があります。このアイデアは、AlanBursteinのソリューションの中心でした。また、関数dbo.GetNumsAlanCharlieItzikBatch(パート1から)、関数dbo.GetNumsJohn2DaveObbishAlanCharlieItzikおよびdbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(パート2から)など、カバーした他のいくつかのソリューションでもこれに依存しました。例として、垂直消去ロジックを使用したベースラインソリューションとしてdbo.GetNumsAlanCharlieItzikBatchを使用します。
このソリューションでは、列ストアインデックスを持つダミーテーブルとの結合を使用して、バッチ処理を取得します。ダミーテーブルを作成するコードは次のとおりです。
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
そして、これがdbo.GetNumsAlanCharlieItzikBatch関数の定義を含むコードです:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO 次のコードを使用して、1億行で関数のパフォーマンスをテストし、計算結果列n(ROW_NUMBER関数の結果の操作)をn順に返します。
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
このテストで得た時間統計は次のとおりです。
CPU時間=9328ミリ秒、経過時間=9330ミリ秒。次のコードを使用して、1億行で関数のパフォーマンスをテストし、列rn(直接、操作されていない、ROW_NUMBER関数の結果)をrn順に返します。
DECLARE @n AS BIGINT; SELECT @n = rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY rn OPTION(MAXDOP 1);
このテストで得た時間統計は次のとおりです。
CPU時間=7296ミリ秒、経過時間=7291ミリ秒。このソリューションに組み込まれている重要なアイデアを確認しましょう。
列除去ロジックに依存して、alanは、数値シリーズを含む1つの列だけでなく、3つの列を返すというアイデアを思いつきました。
- 列rn 1で始まるROW_NUMBER関数の操作されていない結果を表します。計算は安価です。これは、定数を指定する場合と、関数への入力として非定数(変数、列)を指定する場合の両方で順序を保持します。これは、外部クエリがORDER BY rnを使用する場合、プランに並べ替え演算子が含まれないことを意味します。
- 列n @low、定数、およびrownum(ROW_NUMBER関数の結果)に基づく計算を表します。関数への入力として定数を提供する場合、これはrownumに関して順序を保持します。これは、定数畳み込みに関するチャーリーの洞察のおかげです(詳細についてはパート1を参照)。ただし、定数畳み込みが得られないため、入力として非定数を指定する場合は順序を保持しません。これについては、警告に関するセクションの後半で説明します。
- 列op nを逆の順序で表します。これは計算の結果であり、順序を保持するものではありません。
列除去ロジックに依存して、1で始まる一連の数値を返す必要がある場合は、列rnを照会します。これは、nを照会するよりも安価です。 1以外の値で始まる一連の数値が必要な場合は、nを照会して、追加コストを支払います。数値列で並べ替えられた結果が必要な場合は、入力として定数を使用して、ORDERBYrnまたはORDERBYnのいずれかを使用できます。ただし、入力として非定数を使用する場合は、必ずORDERBYrnを使用する必要があります。安全を期すために結果を注文する必要がある場合は、常にORDERBYrnの使用に固執することをお勧めします。
水平方向の単位の削除の考え方は、垂直方向の単位の削除の考え方に似ていますが、列のセットではなく行のセットにのみ適用されます。実際、Joe Obbishは、彼の関数dbo.GetNumsObbish(パート2から)でこのアイデアに依存しており、さらに一歩進んでいきます。彼のソリューションでは、Joeは、各クエリのWHERE句のフィルタを使用してサブレンジの適用可能性を定義し、数値の互いに素なサブレンジを表す複数のクエリを統合しました。関数を呼び出して、目的の範囲の区切り文字を表す定数入力を渡すと、SQL Serverはコンパイル時に適用できないクエリを排除するため、計画にはそれらが反映されません。
水平単位の削除、コンパイル時と実行時の比較
おそらく、より一般的なケースで水平単位の除去の概念を示すことから始めて、コンパイル時と実行時の除去の重要な違いについても説明することをお勧めします。次に、そのアイデアをナンバーシリーズの課題に適用する方法について話し合うことができます。
この例では、dbo.T1、dbo.T2、dbo.T3という3つのテーブルを使用します。次のDDLおよびDMLコードを使用して、これらのテーブルを作成してデータを設定します。
DROP TABLE IF EXISTS dbo.T1, dbo.T2, dbo.T3; GO CREATE TABLE dbo.T1(col1 INT); INSERT INTO dbo.T1(col1) VALUES(1); CREATE TABLE dbo.T2(col1 INT); INSERT INTO dbo.T2(col1) VALUES(2); CREATE TABLE dbo.T3(col1 INT); INSERT INTO dbo.T3(col1) VALUES(3);
上記の3つのテーブル名のいずれかを入力として受け入れ、要求されたテーブルからデータを返すdbo.OneTableというインラインTVFを実装するとします。水平単位除去の概念に基づいて、次のような機能を実装できます。
CREATE OR ALTER FUNCTION dbo.OneTable(@WhichTable AS NVARCHAR(257)) RETURNS TABLE AS RETURN SELECT col1 FROM dbo.T1 WHERE @WhichTable = N'dbo.T1' UNION ALL SELECT col1 FROM dbo.T2 WHERE @WhichTable = N'dbo.T2' UNION ALL SELECT col1 FROM dbo.T3 WHERE @WhichTable = N'dbo.T3'; GO
インラインTVFはパラメータの埋め込みを適用することに注意してください。これは、入力としてN'dbo.T2'などの定数を渡すと、インライン化プロセスが@WhichTableへのすべての参照を最適化前の定数に置き換えることを意味します。 。削除プロセスでは、最初のクエリツリーからT1とT3への参照を削除できるため、クエリの最適化により、T2のみを参照するプランが作成されます。次のクエリでこのアイデアをテストしてみましょう:
SELECT * FROM dbo.OneTable(N'dbo.T2');
このクエリの計画を図1に示します。
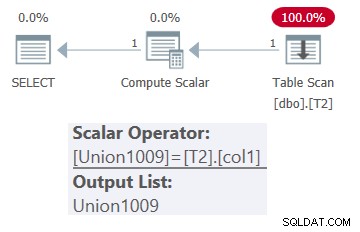 図1:一定の入力を持つdbo.OneTableの計画
図1:一定の入力を持つdbo.OneTableの計画
ご覧のとおり、プランにはテーブルT2のみが表示されます。
非定数を入力として渡す場合は、少し注意が必要です。これは、変数、プロシージャパラメータを使用する場合、またはAPPLYを介して列を渡す場合に当てはまります。入力値はコンパイル時に不明であるか、パラメーター化されたプランの再利用の可能性を考慮する必要があります。
オプティマイザはプランからテーブルを削除することはできませんが、それでもトリックがあります。テーブルにアクセスするサブツリーの上にあるスタートアップフィルター演算子を使用して、@WhichTableの実行時の値に基づいて関連するサブツリーのみを実行できます。次のコードを使用して、この戦略をテストします。
DECLARE @T AS NVARCHAR(257) = N'dbo.T2'; SELECT * FROM dbo.OneTable(@T);
この実行の計画を図2に示します。
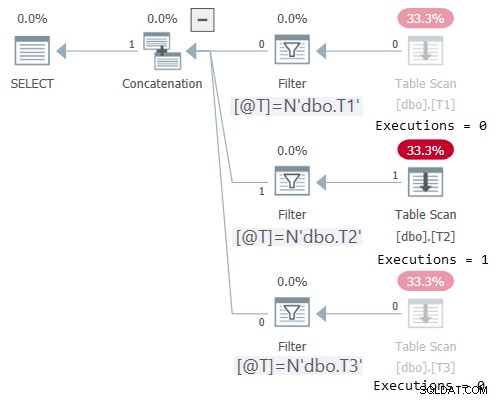 図2:入力が一定でないdbo.OneTableの計画
図2:入力が一定でないdbo.OneTableの計画
Plan Explorerを使用すると、該当するサブツリーのみが実行され(Executions =1)、実行されなかったサブツリーがグレー表示されます(Executions =0)。また、STATISTICS IOは、アクセスされたテーブルのI/O情報のみを表示します。
テーブル「T2」。スキャンカウント1、論理読み取り1、物理読み取り0、ページサーバー読み取り0、先読み読み取り0、ページサーバー先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lobページサーバー読み取り0、lob読み取り-先読みは0を読み取り、LOBページサーバーの先読みは0を読み取ります。数列チャレンジへの水平単位除去ロジックの適用
前述のように、現在垂直方向の除去ロジックを使用している以前のソリューションのいずれかを変更することにより、水平方向の単位除去の概念を適用できます。この例の開始点として、関数dbo.GetNumsAlanCharlieItzikBatchを使用します。
Joe Obbishが水平単位の除去を使用して、数列の関連する互いに素なサブ範囲を抽出したことを思い出してください。この概念を使用して、@ low =1の場合のより安価な計算(rn)を、@ low <> 1の場合のより高価な計算(n)から水平方向に分離します。
その間、fnTally関数にJeff Modenのアイデアを追加して実験することができます。この関数では、範囲が@low =0で始まる場合に、値0のセンチネル行を使用します。
したがって、4つの水平ユニットがあります:
- 0のセンチネル行(@low =0、n =0)
- TOP(@high)行(@low =0、安価なn =rownum、op =@high – rownum
- TOP(@high)行(@low =1、安価なn =rownum、op =@high + 1 – rownum
- TOP(@high – @low + 1)行(@low <> 0 AND @low <> 1、より高価なn =@low – 1 + rownum、およびop =@high + 1 – rownum
このソリューションは、Alan、Charlie、Joe、Jeff、および私自身のアイデアを組み合わせたものであるため、関数dbo.GetNumsAlanCharlieJoeJeffItzikBatchのバッチモードバージョンを呼び出します。
まず、ダミーテーブルdbo.BatchMeがまだ存在することを確認して、ソリューションでバッチ処理を取得することを忘れないでください。存在しない場合は、次のコードを使用してください。
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
dbo.GetNumsAlanCharlieJoeJeffItzikBatch関数を定義したコードは次のとおりです。
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeJeffItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT @low AS n, @high AS op WHERE @low = 0 AND @high > @low
UNION ALL
SELECT TOP(@high)
rownum AS n,
@high - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 0
ORDER BY rownum
UNION ALL
SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 1
ORDER BY rownum
UNION ALL
SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low <> 0 AND @low <> 1
ORDER BY rownum;
GO 重要:水平方向のユニット除去の概念は、垂直方向の概念よりも実装が複雑であることは間違いありません。なぜわざわざするのでしょうか。これは、ユーザーから適切な列を選択する責任がなくなるためです。範囲が1で始まる場合はrnを使用し、それ以外の場合はnを使用することを忘れないようにするのではなく、ユーザーはnという列のクエリについてのみ心配する必要があります。
まず、入力1と100,000,000を一定にしてソリューションをテストし、注文する結果を求めます。
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
この実行の計画を図3に示します。
 図3:dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1、100M)の計画
図3:dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1、100M)の計画
返される列は、直接の操作されていないROW_NUMBER式(Expr1313)に基づいていることに注意してください。また、プランで並べ替える必要がないことにも注意してください。
この実行について、次の時間統計を取得しました。
CPU時間=7359ミリ秒、経過時間=7354ミリ秒。ランタイムは、プランがバッチモード、操作されていないROW_NUMBER式を使用し、並べ替えを使用しないという事実を適切に反映しています。
次に、0〜99,999,999の定数範囲で関数をテストします。
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999) ORDER BY n OPTION(MAXDOP 1);
この実行の計画を図4に示します。
 図4:dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0、99999999)の計画
図4:dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0、99999999)の計画
計画では、結合結合(連結)演算子を使用して、センチネル行を値0および残りの行とマージします。 2番目の部分は以前と同じように効率的ですが、マージロジックは、実行時に約26%のかなり大きな料金がかかるため、次の時間統計が得られます。
CPU時間=9265ミリ秒、経過時間=9298ミリ秒。2〜100,000,001の定数範囲で関数をテストしてみましょう:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001) ORDER BY n OPTION(MAXDOP 1);
この実行の計画を図5に示します。
 図5:dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2、100000001)の計画
図5:dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2、100000001)の計画
今回は、番兵の行部分は無関係であるため、高価なマージロジックはありません。ただし、返される列は、操作された式@low – 1 + rownumであることに注意してください。これは、パラメーターの埋め込み/インライン化と定数畳み込みの後、1+rownumになります。
この実行で取得した時間統計は次のとおりです。
CPU時間=9000ミリ秒、経過時間=9015ミリ秒。予想どおり、これは1で始まる範囲の場合ほど高速ではありませんが、興味深いことに、0で始まる範囲の場合よりも高速です。
0センチネル行の削除
値が0のセンチネル行を使用する手法は、rownumに操作を適用するよりも遅いように思われるため、単純に回避するのが理にかなっています。これにより、アラン、チャーリー、ジョー、そして私自身のアイデアを組み合わせた、単純化された水平方向の除去ベースのソリューションが実現します。このソリューションdbo.GetNumsAlanCharlieJoeItzikBatchを使用して関数を呼び出します。関数の定義は次のとおりです。
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 1
ORDER BY rownum
UNION ALL
SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low <> 1
ORDER BY rownum;
GO 1〜100Mの範囲でテストしてみましょう:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
計画は、予想どおり、図3で前に示したものと同じです。
したがって、次の時間統計を取得しました。
CPU時間=7219ミリ秒、経過時間=7243ミリ秒。0から99,999,999の範囲でテストします:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(0, 99999999) ORDER BY n OPTION(MAXDOP 1);
今回は、図4ではなく、図5で前に示したものと同じプランを取得します。
この実行で取得した時間統計は次のとおりです。
CPU時間=9313ミリ秒、経過時間=9334ミリ秒。2〜100,000,001の範囲でテストします:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(2, 100000001) ORDER BY n OPTION(MAXDOP 1);
ここでも、前に図5に示したものと同じ計画が得られます。
この実行について、次の時間統計を取得しました:
CPU時間=9125ミリ秒、経過時間=9148ミリ秒。非定数入力を使用する場合の警告
垂直方向と水平方向の両方の単位除去手法を使用すると、入力として定数を渡す限り、物事は理想的に機能します。ただし、一定でない入力を渡すとパフォーマンスが低下する可能性があるという警告に注意する必要があります。垂直方向のユニット除去手法は問題が少なく、存在する問題は対処しやすいので、それから始めましょう。
この記事では、垂直単位除去の概念に依存する例として、関数dbo.GetNumsAlanCharlieItzikBatchを使用したことを思い出してください。変数などの非定数入力を使用して一連のテストを実行してみましょう。
最初のテストとして、rnを返し、rn順に並べられたデータを要求します:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = rn FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY rn OPTION(MAXDOP 1);
rnは操作されていないROW_NUMBER式を表すため、この場合、非定数入力を使用するという事実は特別な意味を持ちません。プランで明示的に並べ替える必要はありません。
この実行について、次の時間統計を取得しました:
CPU時間=7390ミリ秒、経過時間=7386ミリ秒。これらの数値は理想的なケースを表しています。
次のテストでは、結果の行をn順に並べます:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
この実行の計画を図6に示します。
 図6:dbo.GetNumsAlanCharlieItzikBatch(@mylow、@myhigh)による注文の計画n
図6:dbo.GetNumsAlanCharlieItzikBatch(@mylow、@myhigh)による注文の計画n
問題がわかりますか?インライン化後、@ lowは@mylowに置き換えられました。@mylowの値である1ではありません。その結果、定数畳み込みは行われなかったため、nはrownumに関して順序を保持しません。これにより、プランで明示的な並べ替えが行われました。
この実行で取得した時間統計は次のとおりです。
CPU時間=25141ミリ秒、経過時間=25628ミリ秒。明示的な並べ替えが不要な場合と比較して、実行時間はほぼ3倍になりました。
簡単な回避策は、Alan Bursteinの元のアイデアを使用して、結果を注文する必要がある場合、rnを返すときとnを返すときの両方で、常にrnで並べ替えることです。
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY rn OPTION(MAXDOP 1);
今回は、プランに明示的な並べ替えはありません。
この実行について、次の時間統計を取得しました:
CPU時間=9156ミリ秒、経過時間=9184ミリ秒。数値は、操作された式を返しているという事実を適切に反映していますが、明示的な並べ替えは発生していません。
dbo.GetNumsAlanCharlieJoeItzikBatch関数など、水平単位除去手法に基づくソリューションでは、非定数入力を使用する場合、状況はより複雑になります。
まず、10個の非常に狭い範囲で関数をテストしましょう:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 10; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
この実行の計画を図7に示します。
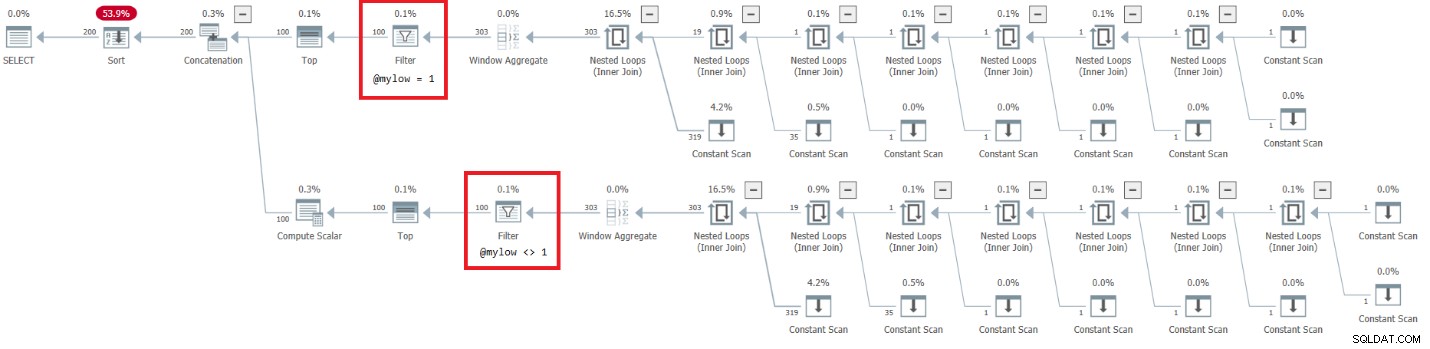 図7:dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow、@myhigh)の計画
図7:dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow、@myhigh)の計画
この計画には非常に憂慮すべき側面があります。フィルタ演算子が下に表示されることを確認します トップオペレーター!入力が一定でない関数を呼び出すと、当然、連結演算子の下のブランチの1つに常に誤ったフィルター条件が設定されます。ただし、両方のTop演算子は、ゼロ以外の行数を要求します。したがって、falseフィルター条件を持つオペレーターの上のTopオペレーターは行を要求し、フィルターオペレーターは子ノードから取得するすべての行を破棄し続けるため、決して満たされることはありません。 Filterオペレーターの下のサブツリーでの作業は、完了するまで実行する必要があります。この場合、これは、サブツリーが4B行を生成する作業を経て、Filterオペレーターが破棄することを意味します。フィルタ演算子が子ノードからの行の要求をわざわざ行うのはなぜか疑問に思いますが、現在はそのように機能しているように見えます。静的な計画ではこれを確認するのは困難です。たとえば、図8に示すように、SentryOneプランエクスプローラーのライブクエリ実行オプションを使用すると、このライブを簡単に確認できます。
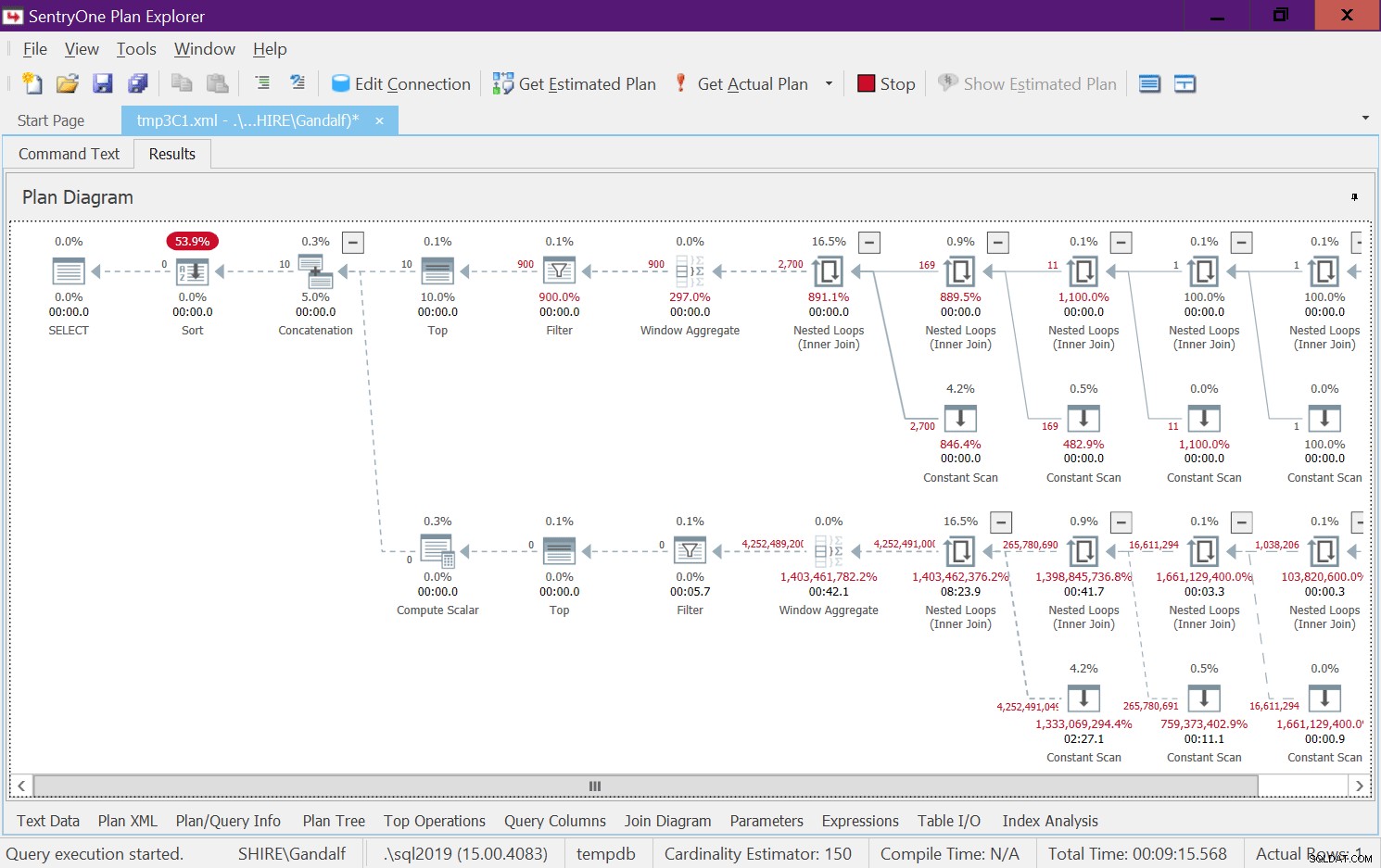 図8:dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow、@myhigh)のライブクエリ統計
図8:dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow、@myhigh)のライブクエリ統計
このテストは私のマシンで完了するのに9:15分かかりました。リクエストは、10個の数値の範囲を返すことであったことを思い出してください。
無関係なサブツリー全体をアクティブ化しないようにする方法があるかどうかを考えてみましょう。これを実現するには、スタートアップのフィルター演算子を上に表示する必要があります。 それらの下ではなく、上位の演算子。テーブル式の基礎、パート4 –派生テーブル、最適化の考慮事項、続きを読むと、TOPフィルターがテーブル式のネスト解除を防ぐことがわかります。したがって、必要なのは、TOPクエリを派生テーブルに配置し、派生テーブルに対して外部クエリでフィルタを適用することだけです。
このトリックを実装する変更された関数は次のとおりです。
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT *
FROM ( SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum ) AS D1
WHERE @low = 1
UNION ALL
SELECT *
FROM ( SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum ) AS D2
WHERE @low <> 1;
GO 予想どおり、定数を使用した実行は、トリックを使用しない場合と同じように動作および実行し続けます。
非一定の入力に関しては、現在は範囲が狭く、非常に高速です。これが10個の数字の範囲でのテストです:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 10; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
この実行の計画を図9に示します。
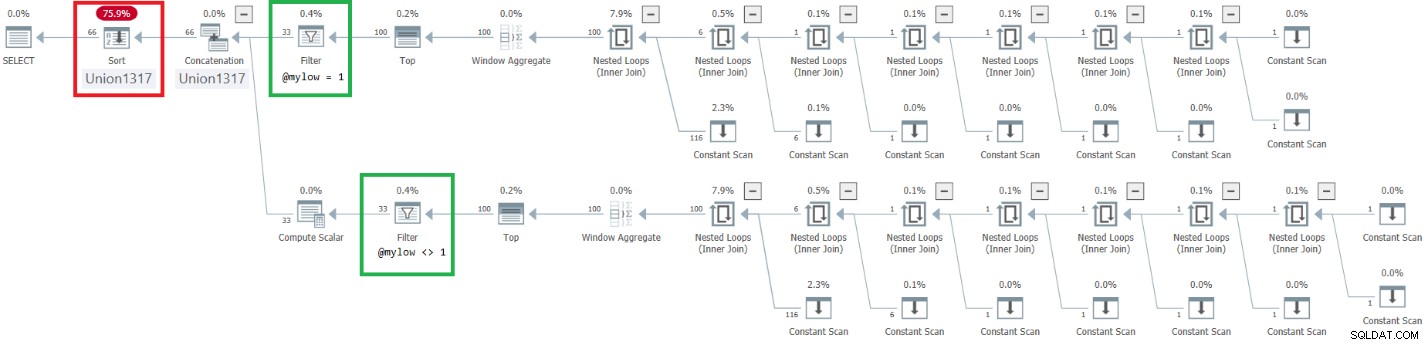 図9:改善されたdbo.GetNumsAlanCharlieJoeItzikBatch(@mylow、@myhigh)<の計画/ em>
図9:改善されたdbo.GetNumsAlanCharlieJoeItzikBatch(@mylow、@myhigh)<の計画/ em>
フィルタ演算子をトップ演算子の上に配置するという望ましい効果が達成されたことを確認します。ただし、順序付け列nは操作の結果として扱われるため、rownumに関して順序保持列とは見なされません。したがって、計画には明示的な並べ替えがあります。
広範囲の1億個の数値で関数をテストします:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
次の時間統計を取得しました:
CPU時間=29907ミリ秒、経過時間=29909ミリ秒。なんて残念なことでしょう。ほぼ完璧でした!
パフォーマンスの概要と洞察
図10に、さまざまなソリューションの時間統計の要約を示します。
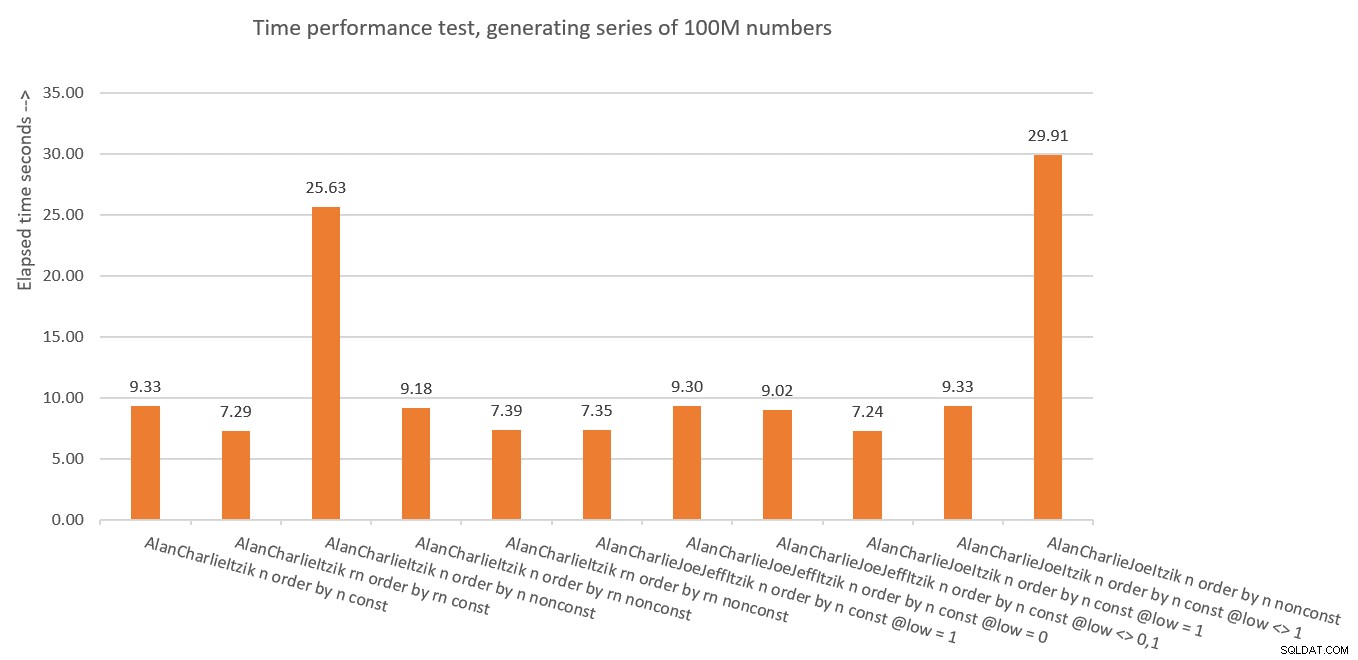 図10:ソリューションの時間パフォーマンスの概要
図10:ソリューションの時間パフォーマンスの概要
では、これらすべてから何を学びましたか?二度とやらないと思います!冗談だ。 dbo.GetNumsAlanCharlieItzikBatchのように、操作されていないROW_NUMBERの結果(rn)と操作された結果(n)の両方を公開する垂直消去の概念を使用する方が安全であることがわかりました。順序付けられた結果を返す必要がある場合は、rnまたはnのどちらを返すかにかかわらず、常にrnで順序付けするようにしてください。
ソリューションが常に入力として定数とともに使用されることが確実である場合は、水平単位除去の概念を使用できます。これにより、ユーザーは値の昇順で1つの列を操作するため、より直感的なソリューションになります。安全のために、関数が非定数入力で使用される場合は、ネスト解除を防ぎ、フィルター演算子をトップ演算子の上に配置するために、派生テーブルでこのトリックを使用することをお勧めします。
まだ終わっていません。来月は、追加のソリューションを引き続き検討します。