方程式のどちらの側にいても、特定の仕事に適した人を見つけるのが難しい場合があります。この投稿では、採用プロセス中に採用担当者と人事部門が整理された状態を維持するのに役立つデータモデルについて説明します。
私たちのほとんどは、ほとんどの場合、求職者として採用プロセスに関与しています。ただし、応募者の技術的知識をテストすることで、採用側に関与していることもわかります。採用には一定の時間がかかり、最終決定に近づくにつれ、応募者のグループはどんどん小さくなっていきます。その結果、その仕事に最適な人物が選ばれるはずです。
採用自体はかなり複雑なので、プロセスのすべての側面をカバーするかなり包括的なデータモデルについて説明します。椅子に腰を下ろして、今日の記事をお楽しみください!
採用プロセスの仕組み
採用プロセスのほとんどの部分は一般的な知識ですが、データモデルに進む前に、それがどのように機能するかを正確に説明します。
-
ニーズの検出
これは、採用プロセスにおいて絶対に必要なことです。経営陣が新しい従業員を雇う必要性を認識していない場合、プロセスはありません。その必要性は、新しい会社の設立、既存の会社の成長、または現在の従業員の退職の結果である可能性があります。
会社が厳密にポジションを定義していない限り(銀行など)、いつ新しい従業員を雇うかを決めるのは必ずしも簡単ではありません。従業員と話をしたり、多くの残業を見たりすると、新入社員に拍車をかけることができます。社内または社外の規制により、特定のスキルセットと関連する実務経験を持つ人(社内の改訂者など)にのみ特定の役職を与えることが義務付けられている場合もあります。
-
ポジションとそれに必要なスキルの概要
このステップのアイデアを得るために、本当によく書かれた職務記述書を考えてください。含まれています:
- ジョブに関連するすべてのタスクのリスト
- 最低限の教育および実務経験の資格
- 職務に不可欠な特定のスキル
- 追加または優先スキル
- 雇用主が申請者に期待することと、申請者がこの仕事に期待できることの要約
- 給与範囲とおそらく福利厚生
この情報は、採用担当者と応募者の両方にとって重要です。資金提供に満足できない応募者がいない場合は、10人の応募者を選考プロセスに招待しても意味がありません。また、職務内容が詳細であるほど、資格のある応募者を引き付けることが容易になります。
-
誰がプロセスを管理し、いつ各タスクを実行するかを定義する
次のステップは、プロセスの各部分が発生する特定の日付を定義することです。また、企業は各ステップに従業員を割り当てる場合があります。会社に人材部門がある場合は、採用プロセスの各部分を管理する可能性がありますが、必要に応じて他の従業員が特定の知識を提供する場合があります(たとえば、ITスペシャリストを採用している場合は、IT部門のマネージャーが候補者を評価する必要があります' 技術的なスキル)。
人事部がない場合は、管理職が担当することが期待できます。中小企業では、これは必要であるだけでなく、望まれています。
-
ジョブの投稿
これで、私たちのサイト、ジョブボードやアグリゲーター、または新聞に職務記述書を投稿する準備が整いました。ジョブポストには、ステップ2にリストされている箇条書きが含まれている必要があります。これは、潜在的な候補者がそのポジションに応募するかどうかを決定するのに役立ちます。職務記述書を正確にすることが不可欠です。説明や期待に合わない仕事のために面接する時間を無駄にしてしまいました。
-
候補者の選択、テスト、インタビュー
応募期間が終了すると、最も関連性の高いスキルセットと経験を持つ応募者が初期評価フェーズ(通常は面接またはテスト)に招待されます。他の応募者には、その仕事に選ばれなかったことが通知されます。大企業は、事前定義された最小数の候補者を初期評価に招待する必要があります。これにより、応募者と会社の両方の時間を節約できます。
中小企業は、最適なものが見つかるまでプロセスを継続することを決定できます。このような場合、適切な候補者が見つかり、他のすべての日付が途中で定義されるまで、申請期間は開いたままになります。
面接とテストのプロセスは、会社の規模と組織によって異なります。人事部門を持つ大企業では、応募者の職務スキルをチェックするための一連のテストが行われる可能性があります。他のテストでは、心理的および人格的特性を測定して、応募者と仕事の一致、応募者と会社の一致、さらには応募者の正気度を判断する場合があります。 ☺
これらのテストは通常、いくつかのステップに分割され、各ステップで応募者の数が減ります。
-
最終面接
このステップは、おそらく上位数名の応募者への面接になります。応募者は自分で話し、能力と個性を示し、会社とポジションが自分に適しているかどうかを判断できるため、これはプロセスの最も重要なステップです。このステップの後、最高の応募者はオファーを受け取ります。彼らが受け入れるならば、そのポジションの採用プロセスは終わります。応募者が求人を拒否した場合、会社は次の選択肢に応募します。
-
中小企業、大企業の採用プロセスに違いはありますか?モデルでそれらをどのように解決しますか?
中小企業、大企業の採用プロセスには一定の違いがあります。さらに、プロセスは採用されるポジションによって異なります。コンテンツマネージャー、鳥類学者、クルーズ船の船長に必要なスキルと経験がどれほど異なるかを考えてください。いくつかの仕事はより多くのテストと面接を持っているでしょう、他のものはほんの少ししか持っていないかもしれません。しかし、結局のところ、それはすべて正しい答えを得ることと応募者をランク付けすることに帰着します。
このモデルでは、すべてのテストとインタビューを同じように扱います。各応募者の回答を保存し、関連する質問と関連付けて、プロセスの各ステップの応募者のスコアを保存します。
-
このデータモデルを使用できるのは誰ですか?
このモデルは非常に具体的であり、採用プロセスにのみ使用する必要があります。ただし、人事部門に限定されるものではありません。このモデルを使用して、プロの採用サービスを実行することもできます。
-
データモデル
データモデルは、5つの主要な主題分野で構成されています。
ジョブ-
応募者、採用担当者、ドキュメント アプリケーションテストの詳細アプリケーションテスト
各主題分野について、記載されているのと同じ順序で個別に説明します。
セクション1:ジョブ
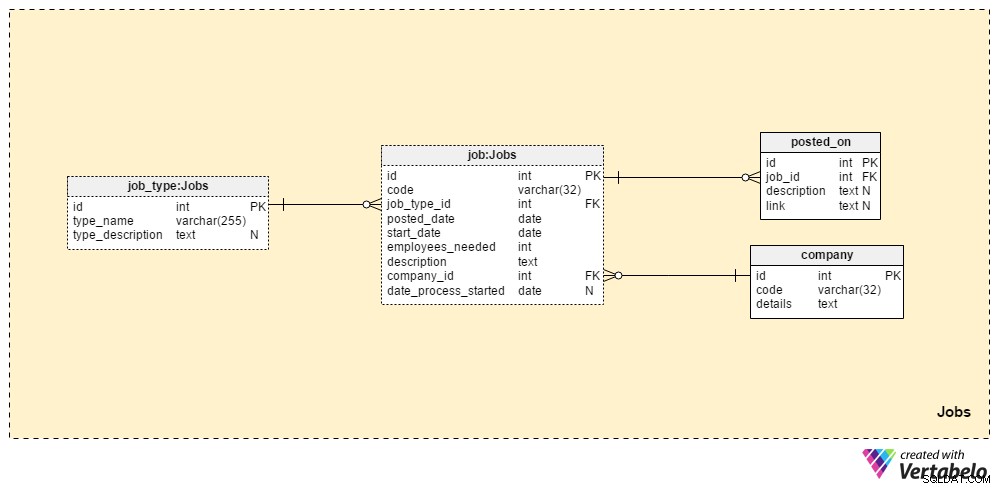
ジョブ セクションには、これまでに投稿したすべてのポジションのすべての詳細が保存されます。 2つのディクショナリテーブル、 company テーブルとjob_type テーブルは、初期設定の一部です。残りの2つのテーブル、 job およびposted_on 、求人情報に関連する「実際の」データが含まれています。
job_type 辞書には、さまざまな一意のジョブタイプのリストが含まれています。 「上級データベース管理者」のような値が期待できます または「ITジャーナリスト」 type_nameに保存されます 属性。 type_description 属性には、ジョブのより詳細な説明を格納できます。
会社 辞書には、私たちが協力しているすべての企業のリストが含まれています。会社のみの従業員を採用する場合、この辞書には会社名のみが含まれます。私たちが採用担当者の場合、私たちを採用したすべての企業の名前が保存されます。
これまでに投稿したすべての職位のリストは、「ジョブ」テーブルに保存されます。この表の属性は次のとおりです。
コード –ジョブを示すために使用される内部UNIQUEID。-
job_type_id–関連するジョブタイプを参照します。 -
posted_date–この役職が掲載された日付。 -
start_date–そのジョブの開始予定日(最初の営業日)。 -
employees_needed–この採用プロセス中に採用したい従業員の数。ほとんどの場合、これの値は「1」になりますが、場合によっては、たとえば新しい会社を立ち上げるとき、または新しい部門を設立するとき–より大きな価値を期待できます。 説明–その位置の詳細な説明。これは、必要な、好ましい、および望ましいすべての職務スキルを一覧表示する場所です。-
company_id–私たちを雇った会社のIDを参照します。私たちが採用担当者である場合、これはcompanyに保存されている会社名を指しますテーブル。それ以外の場合は、自社のIDになります。 -
date_process_started–採用プロセスの開始日。このジョブに関する将来のステップとアクションを定義する必要がある場合、これはNULLになる可能性があります。
このサブジェクトエリアの最後のテーブルは、 posted_onです。 テーブル。 job_idごとに 、 linkを保存します 求人情報と関連するdescription 。このデータを使用して、応募者が私たちの求人情報をどこで見つけるかを知ることができます。
セクション2:応募者、採用担当者、および書類
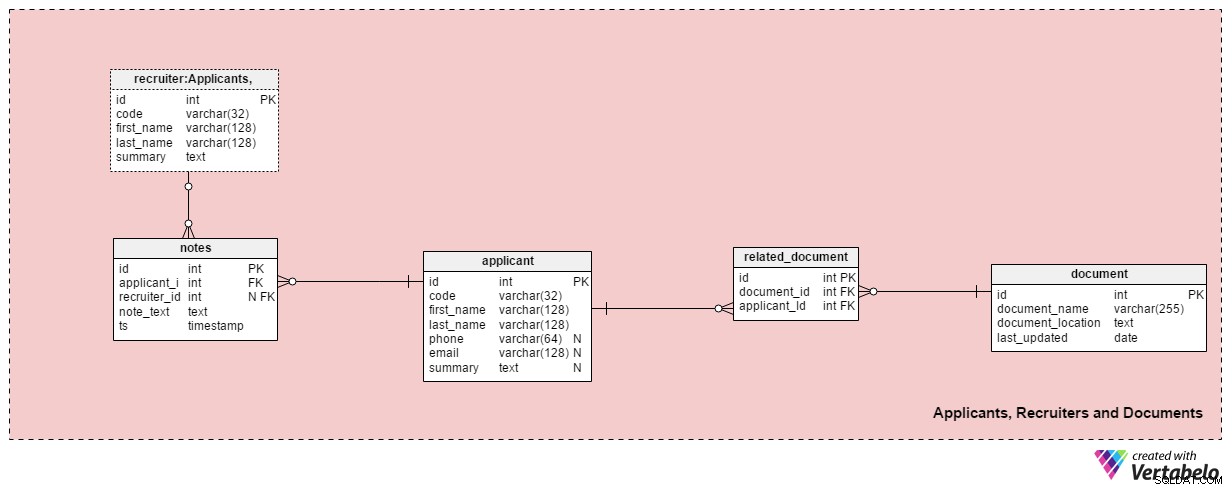
このサブジェクトエリアには、採用担当者、応募者、およびそれらに関連するドキュメントに関する情報を保存するために必要なすべてのテーブルが含まれています。
申請者 表には、これまでに連絡したすべての応募者がリストされています。各申請者は、システム内で「コード」を使用して一意に定義されます。さらに、各申請者の姓名、 phoneを保存します 番号、 email アドレスとその概要 。このテーブルは、特定のニーズに合わせて調整できます。電話番号、電子メール、または住所を追加します。
応募者と利用可能な書類を関連付けます。利用可能なすべてのドキュメント(履歴書または履歴書、学位または卒業証書、成績証明書、証明書など)のリストは、ドキュメントに保存されます。 テーブル。ドキュメントごとに、その名前、場所、最新の更新時刻をシステムに保存します。
related_document を使用して、応募者とドキュメントを関連付けます テーブル。 document_idを形成する2つの外部キーのみを保持します – applyant_id ユニークなペア。
採用担当者 表には、求職に割り当てられる可能性のある従業員、または応募者に関連するメモを入力する従業員がリストされています。各採用担当者は、彼女または彼の codeによって一意に定義されます 。 first_nameなどの基本的な詳細のみを保存します 、 last_name および採用担当者の概要 。
このサブジェクトエリアの最後の表は、メモです。 テーブル。ここには、申請者に関連するすべてのメモが保存されます。 「応募者が会議に出席できなかった」などのメモを保存できます。 または「応募者は最初の面接で素晴らしい成績を収めました」 。メモごとに、そのメモを作成した採用担当者のID、関連する申請者のID、 note_textが保存されます。 、およびメモが作成されたときのタイムスタンプ。
セクション3:テストの詳細
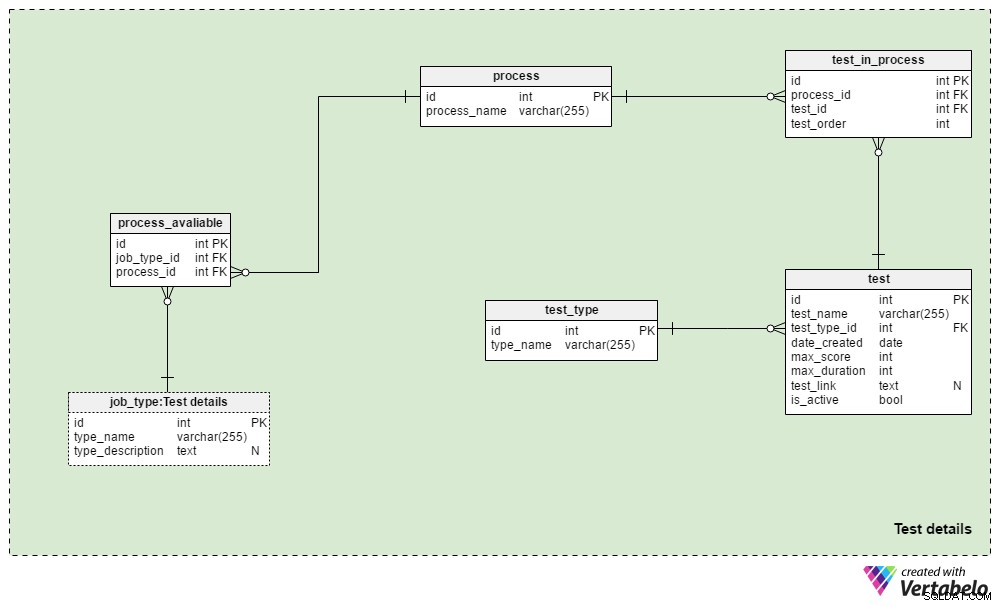
テストの詳細 サブジェクトエリアには、採用プロセスとこれらのプロセス中に使用されるテストを定義するために使用されるテーブルが含まれています。通常、同じ職種に対して常に同じ選択プロセスを使用します。変更は、ビジネス環境で必要な場合にのみ行われます。ジョブタイプごとにいくつかの異なるプロセスを使用できます。ほぼ確実に、異なるジョブタイプに同じプロセスを使用します。
プロセス tableは、UNIQUE process_nameのみを含む単純な辞書です。 属性。これまでに使用した、現在使用しているすべての採用プロセスが一覧表示されます。
プロセスをさまざまな職種に関連付けます。これらの関係をprocess_availableに保存します テーブル。その唯一の属性は、UNIQUEペア job_type_idです。 – process_id 。職種に利用できるプロセスが複数ある場合、これにより採用担当者は1つを選択できます。
test_in_process テーブルは、そのプロセス中のテストの順序を定義するために使用されます。この表の属性は次のとおりです。
-
process_idおよびtest_id–関連するプロセスとテストを参照します。 -
test_order–プロセス内のそのテストまたはステップの序数。process_idと一緒に 、これはテーブルのUNIQUEキーを形成します。プロセス中に一度に実行できるステップは1つだけです。
テスト 表には、採用プロセスで現在および以前に使用されたすべてのテストがリストされています。また、履歴書のレビューと面接もテストとして扱います。質問と回答を定義する必要はありませんが、評価の一部です。テストごとに、以下を保存します:
-
test_name–各テストの一意の指定。 -
test_type_id–test_typeを参照します辞書。 -
date_created–システムでこのテストを作成した日付。 -
max_score–このテストで達成可能な最大スコア。この値は、このテストのすべての正解、または採用担当者が履歴書または面接に与えることができる最高の成績の合計です。 -
max_duration–申請者がテストを完了する必要がある時間(分単位)。 -
test_link–テスト場所へのリンクが含まれています。プロセスでテストを使用しない場合、この値はNULLになる可能性があります。 -
is_active–現在このテストを使用しているかどうかを示します。
test_typeについてはすでに説明しました 辞書。これには、形式ごとのすべてのUNIQUEテスト名が含まれています。 「CVレビュー」 、「オンラインスキルテスト」 、「紙のスキルテスト」 および「インタビュー」 。
このモデルには、テストの質問と回答を保存するために必要な構造は含まれていません。むしろ、この情報を含む場所へのリンクを格納します。 アプリケーションでも同じデザインが使用されます サブジェクトエリア。
セクション4:アプリケーション
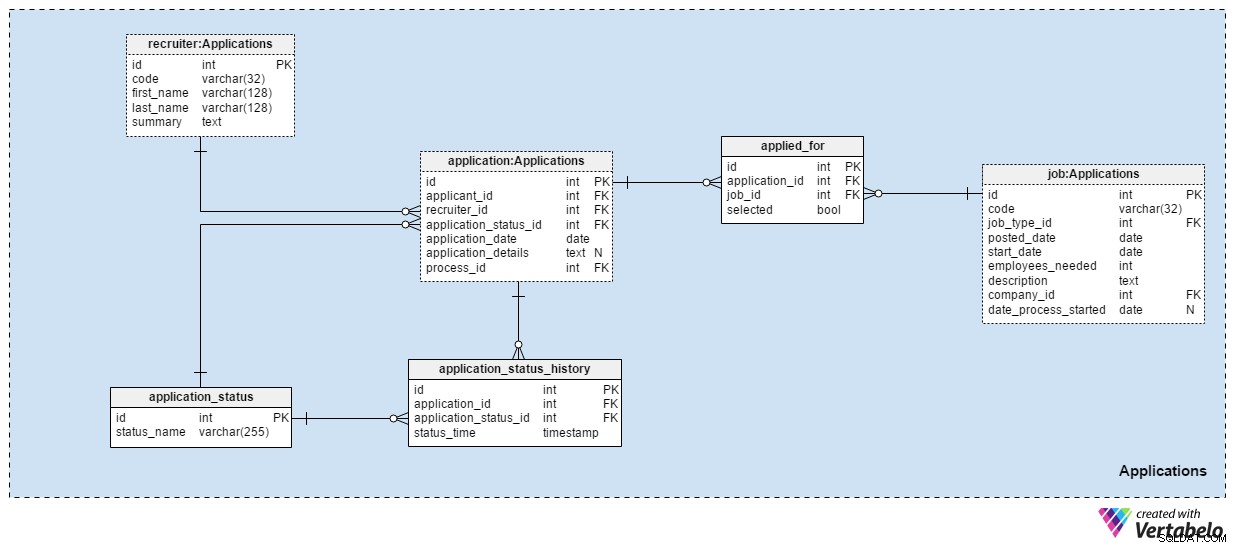
アプリケーション サブジェクトエリアは、このデータモデルでおそらく最も重要です。これまでに言及された他のすべての主題分野は、アプリケーションについて説明しました。これは本物を保存します。
これまでに受け取ったすべてのアプリケーションは、アプリケーションに記録されます テーブル。申請ごとに、関連する申請者のID、採用担当者のID、およびその申請の現在のステータスへの参照を保存します。 application_status_history に新しいエントリを作成すると同時に、このステータスを更新します テーブル。 application_date 属性は関連する日付を保存するために使用され、すべての追加の詳細はテキスト形式で保存されます。 process_id 属性は、そのアプリケーション用に選択されたプロセスへの参照を格納します。
アプリケーションは時間の経過とともにステータスを変更します。すべてのアプリケーションステータスのリストは、 application_statusに保存されます 辞書。唯一の属性はstatus_nameです また、UNIQUE値のみを保持できます。期待される値は次のとおりです。"applied" 、「CVレビュー済み」 、「テスト用に選択」 、「CVレビュー後に拒否されました」 、「テストに合格しました」 、「インタビューに招待されました」 および「申請者によって終了されました」 。
すべてのアプリケーションステータスをapplication_status_historyに保存します テーブル。この表には、アプリケーションへの参照が含まれています テーブルとapplication_status 辞書。正確なstatus_timeも保存します このステータスがアプリケーションに割り当てられたとき。 application_id – status_time ペアは、このテーブルのUNIQUEキーを形成します。
ほとんどの場合、申請者は1回の申請で1つのポジションにのみ申請します。応募者が複数のポジションに応募する可能性があり、選考プロセスで最も適切な役割を選択します。 apply_for テーブルには、UNIQUEペア application_idを保存します – job_id 。また、その申請に関連する申請者が選択されたかどうかも記録します その位置のために。すべてのが選択された 値は「False」に設定されます 選択プロセスの開始時に、各職位ごとに1つだけを「True」に更新します。 。
セクション5:アプリケーションテスト
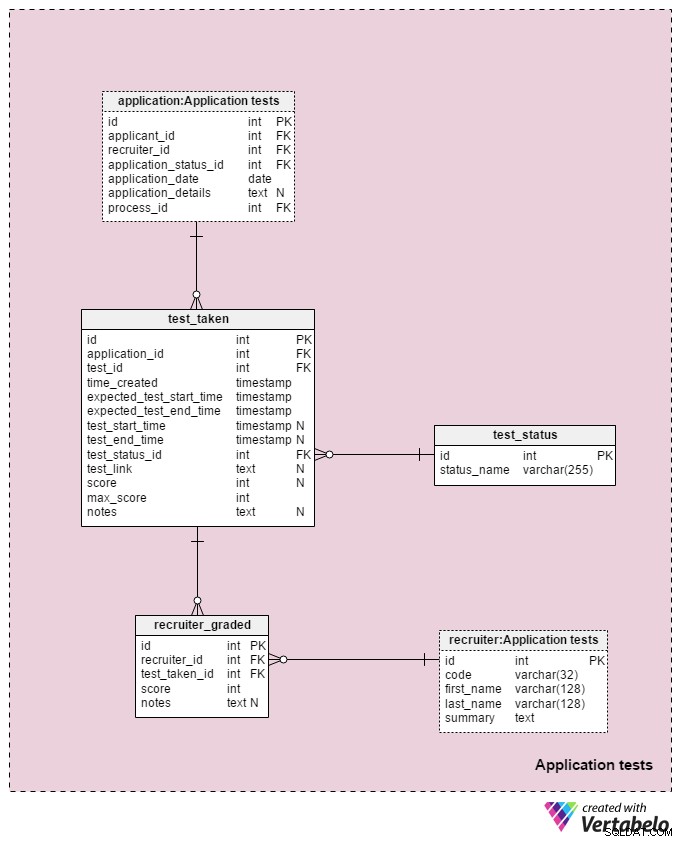
モデルの最後のサブジェクト領域は、選択プロセス中に行われたすべてのテストの結果を保存するために使用されます。このサブジェクトエリアで使用される2つのテーブルは、他のサブジェクトエリアからのコピーです: application および採用担当者 。ここでは、モデルを単純化するために使用されています。
各テストに関連するすべての詳細は、 test_takenに保存されます テーブル。この表には、履歴書のレビューなど、評価される可能性のあるプロセスの他のすべてのステップも含まれています。この表の属性は次のとおりです。
-
application_id–アプリケーションを参照しますテーブル。これは、テストを受験した申請者とのテストに関連しています。 -
test_id–テストを参照しますカタログ。test_in_processを参照することもできますここの表は、行われたテストに関する詳細情報を提供します。この構造が私たちにより多くの柔軟性を提供するので、私はそうしないことに決めました。 (たとえば、申請者が2回または通常の時間外にテストを受けることを許可したい場合) -
time_created–このテストをシステムに挿入した実際の時間。 -
expected_test_start_timeおよびexpected_test_end_time–申請者と話し合った開始時間と終了時間。申請者または採用担当者がテストを延期する必要がある場合は、これらの値を変更できます。 -
test_start_timeおよびtest_end_time–テストの実際の開始時間と終了時間。テストの作成時に、これらにはNULL値が含まれます。申請者がこのテストを開始および終了すると、値が更新されます。 -
test_status_id–test_statusを参照します辞書。 -
test_link–申請者の回答を含むテストへのリンク。申請者がテストを提出すると更新されます。 スコア–そのテストでの申請者のスコア。これは、採用担当者が手動で決定するか(CVレビューなど)、自動的に決定します(すべてのテスト項目のスコアの合計)。また、事前定義されたスケールでスコアリングまたはグレーディングされていないテストの場合、NULL値を保持することもできます。さらに、スケジュールされているがまだ完了していないテストの値がNULLになる可能性があります。-
max_score–テストの達成可能な最大スコア。これは、testに保存されている値と同じです。 。”max_score属性。採用担当者はテストの実施中にテストを変更して、達成できる最大スコアを変更できるため、その値を維持したいと思います。 メモ–その特定のテストに関して採用担当者が入力した追加のメモまたはコメント。
test_idの組み合わせ – application_id – expected_test_start_time 属性は、このテーブルのUNIQUEキーを形成します。新しいテストセッションを追加する前に、関連する申請者とすべての関連する採用担当者のテスト間隔が重複していないかどうかを確認する必要があります。
test_status 辞書には、すべてのUNIQUE status_nameのリストが含まれています それをテストに割り当てることができます。期待される値は次のとおりです。「開始されていません」 、「進行中」 、「正常に完了しました」 、「正常に完了しませんでした」 、「延期」 、"キャンセル" および「申請者がキャンセルされました」 。
モデルの最後のテーブルはrecruiter_graded です 各テストを採点するときに採用担当者が与えたすべての成績を格納するテーブル。したがって、 recruiterへの参照を保存します およびtest_taken テーブル。 スコアも保存します notesと同様に達成 。この情報は、特にテストを手動で採点する場合(つまり、履歴書のレビューやインタビューの場合)に非常に重要です。
本日は、一般的でない例外を含め、選考および採用プロセスのほぼすべての状況をカバーできるデータモデルについて説明しました。
私たちのほとんどは、このトピックに関する専門知識を持っています。あなたが採用担当者の役割を果たしている間、または机の反対側にいたときの経験を共有してください。このモデルはあなたが直面した状況をカバーしていますか?そうでない場合、どのような変更を提案しますか?